





Python入门与实战
Python
一.Python初探
1.Python语言的基本要素
(1)符号和注释
①符号:需要用英文字符,程序前面不能随便加空格
②注释:单行注释用#开头,选中部分Ctrl+/可以代码和注释间相互转化
(2)变量
变量有名字,其值可以存储数据
a=12
b=a#让b的值变得跟a一样
print(a+b)#输出24
a="hello"
print(a)#输出hello
(3)赋值语句
变量=表达式,使变量的值变得跟表达式一样
a,b="he",12
print(a,b)#输出he 12
a,b=b,a
print(a,b)#输出12 he
a=b=c=10
print(a,b,c)#输出10 10 10
2.初步认识字符串
(1)字符串初步
字符串可以且必须用单引号,双引号和三引号括起来;当字符串太长时,可以用\进行分行输出
三双引号字符串中可以包含换行符,制表符等其他字符,双引号中也可以有\n
print("I said:'hello'")#I said:'hello'
print('I said:"hello"')#I said:"hello"
print('''I said:'he said"hello"'.''')#I said:'he said"hello"'.
print("this\
is good!")#this is good!
print("""Tab\tEnter""")#Tab Enter
有n个字符的字符串,编号从左向右为0->n-1,从右往左编号为-1->-n
a="string"
print(a[-1])#g
print(a[0])#s
字符串可以用+号连接
a="ABCD"
b="1234"
c=a+b
d=c+a[1]
print(c)#ABCD1234
print(d)#ABCD1234B
注意字符串不可以修改,在初始化后不可以修改该字符串中任何一个字符
可以用in和not in判断子串
a="hello"
b="python"
print("el" in a)#True
print("py" not in b)#False
(2)字符串和数的转换
x="1234"
y="12.34"
z=1234
a=1.2
b=2.6
print(int(x))#1234,int(x)返回值为x对应的整数,但是不会改变x,要求x一定为整数才能调用int(x)
print(int(a),int(b))#1 2,int(a)还可以作用于数字,用于取整
print(float(y))#12.34,float(y)返回值为y对应的小数,不会改变y,y可以为小数或整数
print(str(z))#1234,str(z)返回值为数字z对应的字符串
print(eval("x+y"))#123412.34把字符串看成一个python表达式并求其值
3.简单的输入输出
(1)输入输出初步
输出语句print(),可以输出一项或多项,输出多项时用,隔开,输出效果为用空格隔开,输出后自动换行
有时不想换行可以在print的括号最后加上end="",缺省的情况下为end="\n"
a="hello"
b="world"
print(a,b,end="")
print(" ok")#hello world ok
输入语句x=input(y),先输出y再等待输入,最后将输入的内容以字符串的形式赋值给x。
要求y一定要是字符串,且赋值输入字符串给x时不带最后的回车
y="input your information\n"
x=input(y)#先显示input your information,后输入1234
print(x)#1234
#输入两个整数并求其和
a=int(input())#输入1
b=int(input())#输入2
print(a+b)#输出3
4.初步认识列表
(1)列表初步
列表可以有0到多个元素,并且可以通过下标访问,下标的概念与字符串相同,列表中的元素类型可以不同
lst=[1,2,"hello",3,'world']
lst[1]=5
print("lst[4]:",lst[4])#lst[4]: world
a=1
print(lst[a])#5
print(len(lst))#5,len(lst)为列表lst的长度
可以用in判断列表中是否有某个元素
lst=[1,2,"hello",3,'world']
print("world" in lst,5 in lst)#True False
输入两个整数并求和
s=input()
numbers=s.split()#对于字符串s以空格,制表符,换行符为分隔符,将s分为若干子串作为列表的每个元素,返回一个列表
print(int(numbers[0])+int(numbers[1]))#输入3 4,输出7
print("1234\t 56\n78".split())#输出['1234','56','78']
二.基本运算、条件分支和输出格式控制
1.算术运算、逻辑运算和分支语句
(1)算术运算
+,-,*,/结果为小数,%取模,//求商结果为整数,**求幂
print(10%8)#2
print(15//4)#3
print(2**3)#8
print(3+-5)#-2
(2)关系运算符,逻辑运算符,逻辑表达式
①关系运算符:==,<,<=,>,>=,!=,比较结果为bool值,True或者False,字符串按照字典排序进行比较
②逻辑运算符:and(与),or(或),not(非),False等于0,True等于1,优先级not>and>or
0,""(空字符串),[](空表)都相当于False;非0数,非空字符串,非空列表都相当于True
③逻辑表达式:逻辑表达式是短路计算的,当表达式的值可以确定时则会停止计算
(3)条件分支语句
if int(input())==5:#注意一定要有":"
print("a",end="")#if语句下缩进相同的语句属于同一个语句组
print("b")#若输入5,则输出ab,否则无输出,转入下一个条件语句
elif not (4<7):#elif即为else if,一旦前一个语句组得以执行,则不再执行剩下分支
print("cd")#中间分支用elif
else:#最后一个分支用else时不需要判断语句,用elif时需要有判断语句
print("OK")
#if语句实例:温度转换程序
tmpStr=input("请输入带有符号的温度值:")
if tmpStr[-1] in ['F','f']:#如果输入华氏温度
c=((float(tmpStr[0:-1])-32)/1.8)
print("转换后的温度是"+str(c)+"C")
elif tmpStr[-1] in ['C','c']:#如果输入摄氏温度
f=float(tmpStr[0:-1])*1.8+32
print("转换后的温度是"+str(f)+"F")
else:
print("输入格式错误")#注意不要把if...elif...else写成多个if
字符串切片:若s为一个字符串,则s[x:y]为从下标x到下标y-1的子串
2.输出格式控制
输出格式控制符与C语言的大致相同,且输出格式控制符仅能作用在字符串的输出中
h=1.746
print("My name is %s,I am %.2fm tall." %("tom",h))#My name is tom,I am 1.75m tall.
#%s用对应的字符串替代,%.nf输出保留n位小数的小数,且遵从四舍六入,五可能舍可能入
#注意"My name is %s,I am %.2fm tall." %("tom",h)是一个完整的字符串
#也可以写成"My name is %s,"%"tom"+"I am %.2fm tall." %h
print("%d%s"%(18,"hello"))#18hello,注意双引号外的百分号%
三.循环语句
1.for循环语句
for
for i in range(5):#range可以看成一个区间range(n)为区间[0,n),range(x,y)为区间[x,y),range(0)range(x,x)为空
print(i,end=" ")#输出0 1 2 3 4,注意for语句后的冒号:
for i in range(0,10,3):#range(x,y,z)从x开始以步长z输出[x,y)中的元素
print(i,end=" ")#输出0 3 6 9
a=['a','b','c']
for i in range(len(a)):#len()可以求字符串,列表,字典,集合的元素个数
print(i,a[i],end=" ")#输出1 a 2 b 3 c
2.break、continue语句
break语句用于跳出循环,continue语句用于直接进入下一层循环,其用法与C语言类似
下为一些for循环语句的例题:
#连续输出26个字母
for i in range(26):
print(chr(ord("a")+i),end="")
#ord(x)为字符x(长度为1的字符串)对应的编码,chr(x)为编码x对应的字符
#求n个整数的和
n=int(input())
total=0
for i in range(n):
total+=int(input())
print(total)
#从小到大或从大到小输出n的因子
n=int(input())
for i in range(1,n+1):#从小到大输出
if n%i==0:
print(i,end=" ")
print()
for i in range(n,0,-1):#从大到小输出
if n%i==0:
print(i,end=" ")
3.while循环语句
count=0
while count<3:
print(count,"小于3")
count+=1
else:
print(count,"大于等于3")
#0 小于3
#1 小于3
#2 小于3
#3 大于等于3
#密码输入系统
while(input("请输入密码:")!="python"):
print("输入密码错误!")
print("输入密码正确!")
#求三个数的最小公倍数
s=input().split()
x,y,z=int(s[0]),int(s[1]),int(s[2])
n=1
while True:#枚举法
if n%x==0 and n%y==0 and n%z==0:
break
n+=1
print(n)
#优化
s=input().split()
x,y,z=int(s[0]),int(s[1]),int(s[2])
n=m=max(x,y,z)
while True:#枚举法,从m开始试,且每隔m试一次
if n%x==0 and n%y==0 and n%z==0:
break
n+=m
print(n)
4.异常处理
常见的异常有:
(1)不合适的转换:int("abc"),float("abc"),int(12.34)
(2)输入已经结束后还执行input()
(3)除法的除数为0
(4)整数和字符串相加
(5)列表下标越界
try:#用try和except处理异常,如果try的语句组出现异常则执行except的语句组,反之则不执行expect的语句组
n=int(input())#输入n为"abc"等不符合要求的字符串时会出现异常
print("hello")
a=100/n#当n为0时会出现异常
print(a)
except:
print("error")#当try的语句组出现异常时,会输出error
print("end")
try:
while True:
s=input()#在pycharm中输入中止的标志为Ctrl+D
print(s)
except:
pass#pass语句不执行任何操作
print("end")
5.循环综合例题
#求斐波那契数列的第k项
k=int(input())
if k==1 or k==2:
print(1)
else:
a1=a2=1
for i in range(k-2):
a1,a2=a2,a1+a2
print(a2)
#求阶乘之和1!+2!+...+n!
n=int(input())
s,f=0,1
for i in range(1,n+1):#进行了优化,每计算一个阶乘都保留其结果参与下一个阶乘的计算
f*=i
s+=f
print(s)
#求不大于n(n>=2)的质数
n=int(input())
print(2)
for i in range(3,n+1,2):#大于2的偶数都是合数,所以只用检验奇数
ok=True
for k in range(3,i,2):
if i%k==0:
ok=False
break
if k*k>i:#大于根号i后不用检验
break
if ok:
print(i)
四.函数和递归
1.函数的概念和用法
def Max(x,y):#def用于定义函数
if(x>y):
return x#用return返回值,一个函数也可以没有返回值
else:
return y#一个函数也可以返回多个值如return x,y
print(Max(4,6))#6
print(Max("about","take"))#take
函数中的变量:在函数中定义的变量不在函数外起到作用,如果函数内的变量x与全局变量x重名,则如果在函数中未对变量x进行赋值,则认为x为全局变量,反之则为函数内部的变量,在函数内可以用global x声明x为全局变量
x=4#全局变量x
def f0():
print(x)#4,这里的x为全局变量x
def f1():
x=8
print(x)#8,这里的x为函数内部的变量x
def f2():
global x#说明函数体中的x为全局变量x
print(x)#4
x=5#改变全局变量x的值
print(x)#5
#def f3():
# print(x)#错误,因为后面对x进行了赋值,则x为函数内部的x,但此时还未对x进行赋值
# x=9
f0()
f1()
f2()
python还有很多内置函数,除了前面所讲,还有abs(x)求x绝对值,max(x),min(x)求列表x中元素的的最大最小值,max(x1,x2...),min(x1,x2...)等
2.递归的概念
def Factorial(n):#求n的阶乘
if n<2:
return 1#终止条件,一个递归函数必须要有终止条件
else:
return n*Factorial(n-1)
#汉诺塔问题
def Hanoi(n,src,mid,dest):#将n个盘子从src柱以mid柱做中转移动到dest柱子上
if n==1:
print(src+"->"+dest)
return#递归中止
else:
Hanoi(n-1,src,dest,mid)#先将n-1个盘子移动到mid柱子上
Hanoi(1,src,mid,dest)#将最底层最大的盘子从src直接移动到dest上
Hanoi(n-1,mid,src,dest)#将mid上的n-1个盘子移动到dest上
n=int(input())
Hanoi(n,'A','B','C')
#雪花曲线的递归定义
#长为size,方向为x的0阶雪花曲线为方向x上一根长为size的线段
#长为size,方向为x的n阶雪花曲线由以下四部分组成
#1.长为size/3,方向为x的n-1阶雪花曲线
#2.长为size/3,方向为x+60的n-1阶雪花曲线
#3.长为size/3,方向为x-60的n-1阶雪花曲线
#4.长为size/3,方向为x的n-1阶雪花曲线从
import turtle#画图要用turtle包,python自带
def snow(n,size):#n是阶数,size是长度,从当前起点出发,在当前方向画一个长度为size阶为n的科赫雪花
if n==0:
turtle.fd(size)#笔沿当前方向前进size
else:
for angel in [0,60,-120,60]:
turtle.left(angel)#笔左转angel度
snow(n-1,size/3)
# turtle.setup(800,600)#窗口缺省位于屏幕正中间,宽800,高600,窗口中央坐标(0,0),笔初始方向为0即为正东方向
# turtle.penup()#抬起笔
# turtle.goto(-300,-50)#将笔移动到(-300,-50)的位置
# turtle.pendown()#放下笔
# turtle.pensize(3)#笔的粗度是3
# snow(3,600)#绘制3阶科赫雪花,长度为600
# turtle.done()#保持绘图窗口
#绘制完整雪花
turtle.setup(800,800)
turtle.speed(1000)#笔的移动速度为1000
turtle.penup()#抬起笔
turtle.goto(-200,100)#将笔移动到(-200,100)的位置
turtle.pendown()#放下笔
turtle.pensize(2)#笔的粗度是2
level=3
snow(level,400)
turtle.right(120)#笔的方向右转120°
snow(level,400)
turtle.right(120)
snow(level,400)
turtle.done()#保持绘图窗口
五.字符串和元组
1.Python变量的指针本质
isinstance函数:
#isinstance(x,y)用于查询数据x是否是类型y
a="1233"
print(isinstance(a,str))#True
print(isinstance(a,int))#False
python中的变量都是指针,赋值的过程即为指针指向某个内存的过程,列表中的元素也可以进行赋值,因此列表中的每个元素都是指针
is运算符和==运算符的区别:
①a is b 为True代表a,b指向同一个内存
②a==b代表a,b指向内存中的值相等
a=[1,2,3,4]
c=a#c指向和a相同的内存
a[2]='ok'#c也会跟着改变
print(c)#[1,2,'ok',4]
#对于list,dict,set类型的变量a,b,我们需要关注a==b与a is b的区别所在
2.字符串详解
转义字符:\与其后面的一个字符一同构成,\n为换行符,\t为制表符等等
print("a\\tb")#a\tb
print(r"a\\tb")#a\\tb,前面加r代表字符串中的\不转义
字符串切片:s[x:y]代表下标x到y-1的子串,字符串切片的方法也适用于元组和列表
s="ABCD"
print(s[1:2])#B
print(s[:3])#ABC,起始下标不写则代表从开头开始
print(s[1:])#BCD,末尾下标不写则代表以末尾结束
print(s[0:3:2])#AC,第三个数代表步长,步长为2
print(s[::-1])#DCBA,可用于字符串反转,步长为负数则从右往左数
字符串的分割:s.split(x)为以x为分隔符,将字符串s分割成一个列表,列表中的每个元素为字符串的子串
#字符串的高级分割
import re#引入re包
a="A*B\n;C:D"
print(re.split('\*|\n|;|:',a))#不同的分隔符用|隔开,re.split()将括号中各符号都当作分隔符,相邻分隔符之间会得出一个空串
#输出['A','B','','C','D']
字符串的函数:
s="AABBAA"
print(s.count('AA'))#2,count用于计算字符串中子串的个数
print(s.lower())#aabbaa,lower用于使字符串中大写转成小写,但是不改变原来字符串,而是返回一个新的字符串
print(s.lower().upper())#AABBAA,upper则为小写转大写
print(s.find("AB"))#1,find返回找到第一个子串的起始下标,找不到则返回-1
print(s.rfind("AB"))#1,rfind则为从后往前查找
try:
s.index("ABA")#index也用于查找,但是如果没找到则会引发异常,rindex同理
except Exception as e:#将异常存入e
print(e)#输出异常结果
a="1234abcd5678"
print(a.find("12",4))#-1,4规定了查找的起始下标
print(a.replace("abcd","1234"))#用1234替代abcd,a本身不会发生变化
print("123.4".isdigit())#False,isdigit判断字符串中的字符是否都是数字
print("ab123".islower())#True,islower判断字符串中的字母是否都是小写字母
print("Aa123".isupper())#False,isupper判断字符串中的字母是否都是大写字母
#strip()用于删去字符串两端的空字符如:空格,\n,\t等,返回一个字符串,但是不改变原字符串
string=" abc\t\n "
string=string.strip()
print(string)#abc
字符串编码:字符串的编码在内存中的编码是unicode的
字符串的格式化:
x="Hello {0} {1:10},you get ${2:0.4f}".format("Mr.","Jack",3.2)#format用于格式化
print(x)#输出Hello Mr. Jack ,you get $3.2000
#{序号:宽度.精度 类型}用于规范输出格式,与format中的变量一一对应
#宽度前还可以加对齐设定,>右对齐,<左对齐,^中对齐
x="Hello {0} {1:^10},you get ${2:0.4f}".format("Mr.","Jack",3.2)#format用于格式化
print(x)#Hello Mr. Jack ,you get $3.2000,实现Jack的中对齐
3.元组
元组:一个元组由数个逗号分隔的值组成,前后的括号可加可不加
元组与列表的区别在于:元组不可修改,不可增删元素,不可对元素进行赋值,不可修改元素的排序,对元组进行处理的速度比列表快
t=12345,54321,"hello"#t为一个元组
print(t)#(12345,54321,"hello")
print(t[0])#12345
u=t,(1,2,3,4,5)#u也是一个元组,且u中的两个元素也都是元组
print(u[1][2])#3
print(len(u))#2,len也可以作用于元组
注意元组的元素的内容可以被修改。
元组的元素本质上是指针,元组的元素不可修改指的是元组元素的指向不可被改变,但指向的内容可修改
t=([1,2,3,4],['a','b'])
t[1][1]='c'#正确,不会报错
print(t)#([1,2,3,4],['a','c'])
empty=()#空元组
a="hello",#注意最后的逗号,说明a是一个只含一个元素的元组
print(a)#("hello",)
#注意只含一个元素的元组,不管加不加括号,最后一定要加上一个逗号!!!
元组的下标访问、切片规则以及运算法则与字符串完全相同
t=("Google","Runoob",1997,2000)
s=(1,2,3,4)
print(t[0])#Google
print(t[1:3])#("Runoob",1997)
print(t[::-1])#(2000,1997,"Runoob","Google")
t+=('a','b','c')
print(t)#("Google","Runoob",1997,2000,'a','b','c')
print(t+s)#("Google","Runoob",1997,2000,'a','b','c',1,2,3,4)
元组的运算、迭代和赋值
x=(1,2,3)*3#重复写三次元组
print(x)#(1,2,3,1,2,3,1,2,3)
print(4 in x)#False
#元组的赋值特殊
x=(1,2,3,4)
b=x#b和x指向同一内存
print(b is x)#True
x+=(100,)#等效于x=x+(100,)在等号右边新建一个元组,改变了x原有的指向,因为不能在元组上增删元素!!!!!
print(x)#(1,2,3,4,100)
print(b)#(1,2,3,4)
print(b is x)#False
元组比大小:类似于字符串按照字典顺序和数字大小一一对应进行比较,但是数字于字符串不能比大小,此时会报错
print((2,"a")>(1,'b','c'))#True
#print((2,"a")>("ab","c"))#runtime error,会报错
#列表大比大小与元组比大小的规则完全相同
我们可以用列表或元组取代复杂的分支结构
#万年历,已知2012年1月25日是星期三,现输入一个2012年1月25日之后的日期,输出该日期是星期几
monthDays=[-1,31,28,31,30,31,30,31,31,30,31,30,31]
days=0#从2012.1.25开始过了多少天
lst=input().split()
year,month,date=int(lst[0]),int(lst[1]),int(lst[2])
for y in range(2012,year):
if y%4==0 and y%100!=0 or y%400==0:#判断是否为闰年
days+=366
else:
days+=365
if year%4==0 and year%100!=0 or year%400==0:
monthDays[2]=29
for i in range(1,month):
days+=monthDays[i]
days+=date
days-=25
print((days+3)%7)
六.列表
1.列表的基本操作
列表是可以增删元素的,并且列表中的元素也可以进行修改
lst=[1,2,3,4,5]
del lst[2]#删减元素
print(lst)#[1,2,4,5]
lst.append(6)#增加元素,括号中的元素被当作一个元素插入进列表尾部
print(lst)#[1,2,4,5,6]
lst2=[lst,7,8]#注意lst2建立之后,与lst还有着联系,lst中的元素改变,lst2中对应的元素也跟着改变
print(lst2)#[[1, 2, 4, 5, 6], 7, 8]
print(lst2[0][1])#2
a=[1,2,3]
b=['a','b','c']
c=a+b#注意c建立之后指向一个新的内存,不再与a,b之间产生联系
print(c)#[1,2,3,'a','b','c']
a[0]=100
print(c)#[1,2,3,'a','b','c']
a=[1,2,3]
c=a
b=['a','b','c']
a+=b#不同于元组,a+=b不等效于a=a+b,a的指向未改变
#a+=b相当于在a后面加上b
#a=a+b相当于用a+b构建一个新的列表,然后使a指向新的内存
print(c)#[1,2,3,'a','b','c'],c与a仍指向同一内存
列表的运算
a=[1,2]
b=a*3#b建立之后与a不再有联系
c=[a]*3#c建立之后,列表中的每个元素都指向a,与a还有联系
#当建立一个新的变量时,如果是以列表或元组的形式对其赋值且[]或()中有一个其他变量,则新变量与这个变量有联系
print(b)#[1,2,1,2,1,2]
print(c)#[[1, 2], [1, 2], [1, 2]]
a.append(3)
print(b)#[1,2,1,2,1,2]
print(c)#[[1, 2, 3], [1, 2, 3], [1, 2, 3]]
print(b.index(1))#0,注意列表只有index用于查找,没有find
#例题
a=[[0]]*2+[[0]]*2#+前后两个[0]不是同一个!!!
a[0][0]=5
print(a)#[[5], [5], [0], [0]]
列表的切片
a=[1,2,3,4]
b=a[1:3]#b创建之后,与a没有任何联系
print(b)#[2,3]
print(a[::-1])#[4,3,2,1]
2.列表的排序
选择排序:基础的排序算法,但是效率较低
def SelectionSort(a):#即为冒泡排序
n=len(a)
for i in range(n-1):#每次从a[i]及其右边的元素中选择最小的元素并将其放在a[i]位置
for j in range(i+1,n):#依次考察a[i]右边的元素
if a[j]<a[i]:
a[i],a[j]=a[j],a[i]
lst=[1,12,4,56,6,2]
SelectionSort(lst)
print(lst)#[1, 2, 4, 6, 12, 56]
python自带的排序函数:
a=[7,5,6,4,3,1,2]
a.sort()#对a进行排序,默认从小到大排,不仅可以对数字进行排序,也可以对于其他数据类型按照字典排序,sort为稳定的排序
print(a)#[1,2,3,4,5,6,7]
a.sort(reverse=True)#从大到小进行排序
print(a)#[7,6,5,4,3,2,1]
b=sorted(a)#将排序好的a赋值给b,但是不改变a
print(b)#[1,2,3,4,5,6,7]
b=sorted(a,reverse=True)#同理,从大到小排序
print(b)#[7,6,5,4,3,2,1]
对于不同的需求,我们可以自定义比较函数用在sort函数上
def myKey(x):
return x%10
a=[25,7,16,33,6,1,2]
a.sort(key=myKey)#key是函数,sort按照对每个元素调用该函数的返回值大小进行排序
print(a)#[1,2,33,4,25,16,7]
b=sorted("This is a test string from Andrew".split(),key=str.lower)#以各个字符串的小写形式比大小
print(b)#['a', 'Andrew', 'from', 'is', 'string', 'test', 'This']
3.复杂列表的自定义排序
(1)lambda表达式
lambda x:x[2],表示一个函数,参数是x,返回值是x[2],相当于是一个匿名函数
k=lambda x,y:x+y#k为一个函数
print(k(4,5))#9
(2)自定义排序
students=[('John','A',15),('Mike','B',12),('Mike','C',18),('Bom','D',10)]#列表中的每个元素都是一个三元组
students.sort(key=lambda x:x[2])#按年龄进行排序
print(students)#[('Bom', 'D', 10), ('Mike', 'B', 12), ('John', 'A', 15), ('Mike', 'C', 18)]
(3)元组的排序
元组的元素不能被修改,因此没有相应的sort函数,但是有sorted函数可以作用于元组,但是返回值是一个列表
4.列表和元组的高级用法
列表的相关函数:
a=[1,2,3,4,1]
a.insert(3,5)#将5插入到下标为3的位置
print(a)#[1,2,3,5,4,1]
a.remove(1)#删除第一个值为1的元素
print(a)#[2,3,5,4,1]
a.reverse()#反转a
print(a)#[1,4,5,3,2]
del a[2]#删除a中下标为2的元素
print(a)#[1,4,3,2]
列表映射:
def f(x):
print(x,end="")
return x*x
a=map(f,[1,2,3])#map用于将一个序列映射到另一个序列,返回一个延时求值对象,可以转换成list,tuple,set...
#调用完map后,将序列中每个元素调用f的操作存储下来,并不会执行f(称此为延时求值),因此没有任何输出
print(list(a))#123[1,4,9],将延时求值对象转换为列表,并将每个元素调用f的结果存储到该列表中
print(tuple(a))#(),延时求值对象的操作已经执行完,因此再转换成元组时不会有任何操作,返回空元组
a=list(map(lambda x:x*2,[2,4,6]))
print(a)#[4,8,12]
#map可以用于简化输入
x,y,z=map(int,input().split())#输入1 2 3
print(x,y,z)#1 2 3
列表过滤:
def f(x):
return x%2==0
a=tuple(filter(f,[1,2,3,4,5]))#filter用于筛选出序列中调用f返回值为True的元素,并返回一个延时求值对象
print(a)#(2,4)
列表生成式:
a=[x*x for x in range(1,11)]
print(a)#[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
b=[x*x for x in range(1,11) if x%2==0]
print(b)#[4, 16, 36, 64, 100]
c=[m+n for m in 'ABC' for n in 'XYZ']
print(c)#['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
d=[[m+n for m in 'ABC']for n in 'XYZ']
print(d)#[['AX', 'BX', 'CX'], ['AY', 'BY', 'CY'], ['AZ', 'BZ', 'CZ']]
#同理有元组生成式
e=tuple(x*x for x in range(1,11))#元组生成式前面必须有tuple
print(e)#(1, 4, 9, 16, 25, 36, 49, 64, 81, 100)
二维列表的定义:
matrix=[[1,2,3],[4,5,6],[7,8,9]]#正确,相当于一个矩阵
print(matrix[1][1])#5
matrix=[[0 for i in range(3)] for i in range(3)]#利用列表生成式生成二维列表
print(matrix)#[[0,0,0],[0,0,0],[0,0,0]]
lst=[]
for i in range(3):
lst.append([0]*4)
print(lst)#3行4列的元素全为0的矩阵
#同理可以定义二维元组
列表的拷贝:
a=[1,2,3,4]
b=a[:]#b是a的拷贝,b和a指向不同的对象,但是未能进行深拷贝
b+=[10]
print(b)#[1,2,3,4,10]
print(a)#[1,2,3,4]
列表的深拷贝:
a=[1,[2]]
b=a[:]
print(b)#[1,[2]]
a[1].append(3)
print(b)#[1,[2,3]],说明未能深拷贝
#深拷贝的实现
import copy#引入copy包
a=[1,[2]]
b=copy.deepcopy(a)#进行深拷贝
a[1].append(3)
print(b)#[1,[2]]
元组和列表的互转:
a=[1,2,3]
b=(1,2,3)
print(tuple(a))#(1,2,3)
print(list(b))#[1,2,3]
[x,y,z]=a
print(x,y,z)#1 2 3
(x,y,z)=b
print(x,y,z)#1 2 3
元组列表和字符串的互转:
a=list("hello")
print(a)#['h', 'e', 'l', 'l', 'o']
b=tuple("hello")
print(b)#('h', 'e', 'l', 'l', 'o')
c="".join(['a','b','c'])
print(c)#abc
d="".join(('a','b','c'))
print(d)#abc
5.例题
#成绩排序:输入n个人名和成绩,按照成绩从大到小进行排序,如果成绩相等,则按照姓名的字典序从小到大排
n=int(input())
a=[]
for i in range(n):
s=input().split()
a.append((s[0],int(s[1])))
a.sort(key=lambda x:(-x[1],x[0]))
for i in a:
print(i[0],i[1])
#图像模糊处理:给定n行m列的图像各像素点的灰度值,要求用如下方法对其进行模糊处理
#1.四周最外侧的像素点灰度值不变
#2.中间各像素点的灰度值为该像素点与其上下左右各像素点灰度值的平均
import copy
n,m=map(int,input().split())
a=[]#建立一个空表
for i in range(n):#建立二维列表
lst=list(map(int,input().split()))
a.append(lst)
b=copy.deepcopy(a)#b为a的深拷贝
for i in range(1,n-1):#处理中间像素点
for j in range(1,m-1):
b[i][j]=int((a[i][j]+a[i-1][j]+a[i][j-1]+a[i+1][j]+a[i][j+1])/5)
for i in range(n):
for j in range(m):
print(b[i][j],end=" ")
print("")
七.字典和集合
1.字典的基本概念
字典中的每个元素由“键:值”两部分组成,每个元素的键是唯一且不与其他元素的键相同的,可以根据键对元素进行快速查找
键必须是不可变的数据类型,如字符串,整数,小数,元组;而列表,集合,字典等可变数据类型不能作为字典元素的键
dt={'Jack':18,"Mike":19,128:37,(1,2):[4,5]}#dt为一个字典
print(dt['Jack'])#18,输出键为Jack的元素的值
dt[128]=40#将键为128的元素的值改为40
print(dt)#{'Jack': 18, 'Mike': 19, 128: 40, (1, 2): [4, 5]}
#print(dt['c'])#error
字典的增删元素:
dt={'Jack':18,"Mike":19,128:37,(1,2):[4,5]}#dt为一个字典
del dt['Mike']#删除键为Mike的元素
print(dt)#{'Jack': 18, 128: 37, (1, 2): [4, 5]}
dt['Sam']=17#增加键为Sam值为17的元素
print(dt)#{'Jack': 18, 128: 37, (1, 2): [4, 5], 'Sam': 17}
字典元素不能重复,如果重复则保留后一个出现的元素:
a=(1,2,3)
b=(1,2,3)
dt={a:10,b:20,(1,2,3):30}
print(dt)#{(1,2,3):30}
字典的构造:
lst=[('Jack',18),('Mike',19)]#只有元素为含有两个元素的列表或元组的列表或元组才能转为字典
dt=dict(lst)#将列表转为字典
print(dt)#{'Jack': 18, 'Mike': 19}
dt=dict(name='Sam',height=177)#此种方法只适用于键都为字符串的字典的创建,且键不带引号
print(dt)#{'name': 'Sam', 'height': 177}
2.字典的相关函数
dt={'name':'Gumby','age':42,'GPA':3.5}
print(dt.keys())#dict_keys(['name', 'age', 'GPA']),keys()取字典键的序列
print(dt.items())#dict_items([('name', 'Gumby'), ('age', 42), ('GPA', 3.5)]),items()取字典元素序列
print(dt.values())#dict_values(['Gumby', 42, 3.5]),values()取字典值的序列
#注意上述序列不是list、tuple或set
dt.pop('GPA')#删除键为‘GPA’的元素,如果未找到则产生异常
print(dt)#{'name': 'Gumby', 'age': 42}
dt.clear()#清空字典
print(dt)#{}
遍历字典:
dt={'name':'Gumby','age':42,'GPA':3.5}
for x in dt.items():#此时x为元组
print(x,end=" ")#('name', 'Gumby') ('age', 42) ('GPA', 3.5)
字典的浅拷贝与深拷贝:
#浅拷贝
x={'username':'wzt',1978:[1,2,3]}
y=x.copy()
y['username']='hust'#不影响x
y[1978].remove(2)#影响x
print(y)#{'username': 'hust', 1978: [1, 3]}
print(x)#{'username': 'wzt', 1978: [1, 3]}
#深拷贝
import copy
z=copy.deepcopy(x)#深拷贝
z[1978].remove(1)#不影响x
print(z)#{'username': 'wzt', 1978: [3]}
print(x)#{'username': 'wzt', 1978: [1, 3]}
3.字典例题
#统计单词频率,输入若干单词,按照出现频率从大到小输出频率和单词,如果频率相同则按照字典序从小到大输出
dt={}#空字典
while True:
try:
wd=input()
# if wd in dt:
# dt[wd]+=1#如果有元素wd,则给其次数加一
# else:
# dt[wd]=1#如果没有元素wd,则在字典中插入wd
dt[wd]=dt.get(wd,0)+1#如果dt中有键为wd的元素,则返回该元素的值,否则返回后一个数0
except:
break
result=[]#空列表用于存储结果
for i in dt.items():
result.append(i)#i为元组,i[0]为单词,i[1]为数字
result.sort(key=lambda x:(-x[1],x[0]))
for x in result:
print(x[1],x[0])
4.集合
集合的定义同数学上的集合,集合中元素类型可以不同,不会有重复的元素,可以增删元素,集合中的元素类型应为可变数据类型如:字符串,整数,小数,复数,元组,而不能为列表、字典和集合
集合的作用是可以快速地判断某个元素是否在一堆元素里面
集合的构造:
x=set([])#构造一个空集合,也可以写成set()
a={1,2,2,"hello",(1,3)}#a是一个集合,会自动去重
print(a)#{'hello', 1, 2, (1, 3)},注意集合中的元素是没有顺序的!!!!
#print(a[2])#error,因为集合没有顺序,所以无法用下标进行访问
b=[1,2,3,4]#b为列表
c=('a','b','c')#c为元组
d={1:2,'OK':3,(1,2):7}#d为字典
print(set(b))#{1, 2, 3, 4},用列表构建集合
print(set(c))#{'b', 'c', 'a'},用元组构建集合
print(set(d))#{1, (1, 2), 'OK'},用字典构建集合,只取键
集合常用的函数:
a={1,2,3,4}#a为一个集合
b=[5,6,7,8]
a.add(5)#在集合中插入元素5,如果集合中已存在5,则不添加
print(a)#{1, 2, 3, 4, 5}
a.remove(2)#在集合中删除2,如果集合中没有2,则产生异常
print(a)#{1, 3, 4, 5}
a.update(b)#将序列b中的元素加入集合
print(a)#{1, 3, 4, 5, 6, 7, 8}
c=a.copy()#返回集合的浅拷贝
print(c)#{1, 3, 4, 5, 6, 7, 8}
a.clear()#清空集合
print(a)#set(),注意空集合用set()表示,空字典用{}表示
集合的逻辑运算:
a={1,2,3}
b={2,3,4}
print(1 in a)#True
print(a|b)#{1,2,3,4},a|b为a与b的并集
print(a&b)#{2,3},a&b为a与b的交集
print(a-b)#{1},a-b为a与b的差
print(a^b)#{1,4},a^b为a与b的对称差,即a|b-a&b
集合的比较:
a={1,2,3}
b={1,2,3,4,5}
print(a==b)#False,判断a,b是否相同
print(a!=b)#True,判断a,b是否不同
print(a<=b)#True,判断a是否是b的子集
print(a<b)#True,判断a是否是b的真子集
八.文件读写和文件夹操作和数据库
1.文本文件的读写
创建文本文件并写入内容:
a=open("F:\\test.txt","w")#open用于按照路径打开或创建文件,w表示打开文件的方式为写,如果原文件存在则会覆盖原文件
a.write("hello,world\n")#write用于向文件中写入内容
a.write("good!")
a.close()#open之后一定要记得close
#操作完之后F:\\test.txt中的内容为
#hello,world
#good!
读取现有文件:
f=open("F:\\test.txt","r")#r表示打开文件的方式为读,如果文件不存在则会产生异常
lines=f.readlines()#readlines()返回一个列表,每个元素都是一个字符串,代表文件文本内容的一行(带\n)
line1=f.readline()#readline()只读取一行,返回一个字符串
line2=f.readline()
f.close()
for x in lines:
print(x,end="")#注意列表每个元素都带有换行符
#输出结果为F:\\test.txt中的内容
#hello,world
#good!
f=open("F:\\test.txt","r")
line1=f.readline()#readline()只读取一行,返回一个字符串,结尾如果有换行符会带\n
line2=f.readline()
f.close()
print(line1,end="")#hello,world
print(line2,end="")#good!
f=open("F:\\test.txt","r")
txt=f.read()#将整个文件内容读入一个字符串txt
f.close()
print(txt)
#输出结果为F:\\test.txt中的内容
#hello,world
#good!
在文件中添加内容:
f=open("F:\\test.txt","a")#a表示向文件中添加新内容而不覆盖原内容,若文件不存在就创建文件
f.write("OK\n")#向新文件中添加OK
f.close()
#操作完之后F:\\test.txt中的内容为
#hello,world
#good!
#OK
2.文本文件的编码
常见文件的编码有gbk和utf-8两种,ANSI对应gbk,创建和读写文件时都可以指定编码,如果不指定则默认为缺省的编码
.py文件必须存成utf-8格式才能运行,如果存成ansi格式(即为gbk格式),应在文件开头写#coding =gbk
f=open("F:\\test.txt","r",encodeing="utf-8")#以utf-8的编码格式打开文件
f.close()
3.文件的路径
相对路径:文件路径没有包含盘符
当前文件夹:一般来说.py文件所在的文件夹就是当前文件夹
f=open("../../test.txt","r")#文件在当前文件夹的上两层文件夹里面,/等价于\\
f.close()
f=open("/tmp/test.txt","r")#文件在当前盘符的根文件夹下
f.close()
#可以获取当前文件夹
import os
print(os.getcwd())#输出当前.py文件所在文件夹
绝对路径:文件路径指明了盘符
4.文件夹操作
python的文件夹和文件操作函数:
import os#引入os包
import shutil#引入shutil包
os.chdir(x)#将程序当前文件夹设置为x
os.getcwd()#求程序当前文件夹
os.listdir(x)#返回一个列表,列表元素是文件夹x中所有文件和子文件夹的名字
os.mkdir(x)#创建文件夹x
os.path.getsize(x)#获取文件x的大小
os.path.isfile(x)#判断x是不是文件
os.remove(x)#删除文件x
os.rmdir(x)#删除文件夹,前提是文件夹为空文件夹
os.rename(x,y)#将文件或文件夹x改名为y,也可以起到移动文件的作用
shutil.copy(x,y)#拷贝文件x到文件y,如果y已存在,则会覆盖y
有时文件夹非空但也想要删除文件夹,则不能调用os.rmdir(x),可以自己定义删除文件夹的函数:
#递归删除文件夹
import os
def powerRmdir(path):#连根删除文件夹path,删除的文件夹不能恢复,慎用
lst=os.listdir(path)#将当前文件夹下的文件和子文件夹名存储至lst
for x in lst:#x只是文件名和文件夹名,不包含路径
actualFileName=path+"/"+x#构建完整路径
if os.path.isfile(actualFileName):#actualFileName是文件
os.remove(actualFileName)
else:#actualFileName是文件夹
powerRmdir(actualFileName)
os.rmdir(path)#最后删除空文件夹
获取文件夹总大小也可以同理自己定义函数:
#递归获取文件总大小
def getTotalSize(path):
total=0
lst=os.listdir(path)
for x in lst:#x只是文件名和文件夹名,不包含路径
actualFileName=path+"/"+x#构建完整路径
if os.path.isfile(actualFileName):#actualFileName是文件
total+=os.path.getsize(actualFileName)
else:#actualFileName是文件夹
total+=getTotalSize(actualFileName)
return total
5.命令行参数
Win+R并输入cmd即可打开控制台,输入python ×××.py即可运行×××.py,注意需要先将控制台转到.py当前文件夹下
当.py文件需要输入参数时,我们希望可以直接在命令行直接输入,可进行如下操作:
#求和程序,假设.py文件的文件名为pythonfile.py且在命令行输入python main.py 3 4
import sys#引入sys包
for x in sys.argv:
print(x)#argv即为一个列表,列表的参数为命令行输入的字符串
#输出结果:
#main.py
#3
#4
print(int(sys.argv[1])+int(sys.argv[2]))#7
6.文件处理实例
#统计文章中单词的词频
#运用命令行输入python main.py 源文件 结果文件
#对源文件进行单词词频分析,将结果写入结果文件,单词按照字典排序
import sys#用于命令行输入
import re#用于分隔源文件
def countFile(filename,words):#处理源文件,将处理结果存入字典words
try:
f=open(filename,"r",encoding="utf-8")
except Exception as e:#如果打开文件失败,则报错并返回
print(e)
return 0
txt=f.read()#将整个文件内容读入字符串txt
f.close()
splitChars=set([])#分割串的集合
for c in txt:
if not(c>='a' and c<='z' or c>='A' and c<='Z'):
splitChars.add(c)
splitStr=""#用于re.split的正则表达式
for c in splitChars:
if c in ['.','?','!','"',"'",'(',')','[',']','{','}','|','*','$','\\','^']:
#这些字符比较特殊,在正则表达式中需要加\
splitStr+="\\"+c+"|"
else:
splitStr+=c+"|"
splitStr+=" "#'|'后面必须要有东西,空格多写一遍没关系
lst=re.split(splitStr,txt)#将文章分割为若干单词
for x in lst:
if x=="":#忽略空串
continue
else:
lx=x.lower()
words[lx]=words.get(lx,0)+1#将lx的信息整合到字典,没有则插入lx,有则次数+1
return 1
result={}#空字典用于存储结果
if countFile(sys.argv[1],result)==0:#处理源文件
exit()
lst=list(result.items())#将字典信息转为列表,写为list(result)只会保留键
lst.sort()#对列表中的二元组进行排序
f=open(sys.argv[2],"w")
for x in lst:
f.write("%s\t%d\n" % (x[0],x[1]))
f.close()
7.数据库和SQL语言简介
(1)数据库:
数据库可以存放大量数据,并且提供了方便快捷的检索手段,一个数据库可以是一个文件
一个数据库中可以有多张表,每张表又又不同的字段,字段又有其相应的类型
(2)SQL语言:
SQL命令是用于进行数据库操作的标准语句
#创建数据库并写入数据
import sqlite3#提供了数据库功能
db=sqlite3.connect("F:/tmp/test.db")#连接数据库,若不存在则自动创建
cur=db.cursor()#获取光标,对数据库的操作一般要通过光标
sql='''CREATE TABLE if not exists students(id integer primary key,name text,gpa real,birthday date,age integer,picture blob)'''#创建表student的SQL命令
#primary key用于声明主关键字,integer表整数,real表小数,date表日期,blob表二进制,它们是字段的数据类型
cur.execute(sql)#执行SQL命令
sql1='''INSERT INTO students VALUES(1000,'张三',3.81,'2000-09-12',18,null)'''#插入数据的SQL命令
#在没有相应数据时,只有在SQL命令中才可以写成null,在元组中一般写成None
cur.execute(sql1)#执行SQL命令
mylist=[(1700,'李四',3.25,'2001-12-01',17,None),
(1800,'王五',3.35,'1999-01-01',18,None)]
for s in mylist:#依次插入mylist中的每个记录
cur.execute('INSERT INTO students VALUES(?,?,?,?,?,?)',(s[0],s[1],s[2],s[3],s[4],s[5]))#?对应于后面某项
db.commit()#落实对数据库的修改,真正地写入数据库,一定要写!!!
cur.close()#关闭光标
db.close()#关闭数据库
用sqlite3.exe打开.db文件时,输入select * from 表名;即可显示表中信息,注意一定要加分号
(3)数据库的查询和修改
数据库的查询:
import sqlite3
db=sqlite3.connect("F:/tmp/test.db")#连接数据库,若不存在则自动创建
cur=db.cursor()#获取光标,对数据库的操作一般要通过光标
sql="SELECT * FROM students"#检索students表中的全部记录,*代表全部
cur.execute(sql)#提取出的记录存储在光标中
for x in cur.fetchall():#fetchall取得所有满足条件的记录,以元组的形式存储
print(x)
#输出结果为数据库中的内容,后续不再做输出
sql1="SELECT * FROM students ORDER BY age"#检索students表中的全部记录,并按年龄排序,后面再加DESC表示按降序排
cur.execute(sql1)
sql2="SELECT name,age FROM students"##检索students表中的全部记录,但每个记录只取name和age两个字段
cur.execute(sql2)
sql3="SELECT * FROM students WHERE name='张三'"#检索students表中的全部name为张三的记录,WHERE表示检索条件
cur.execute(sql3)
sql4="SELECT * FROM students WHERE name='张三' AND age>10"
cur.execute(sql4)
db.commit()#落实对数据库的修改,真正地写入数据库,一定要写!!!
cur.close()#关闭光标
db.close()#关闭数据库
数据库的修改:
import sqlite3
db=sqlite3.connect("F:/tmp/test.db")#连接数据库,若不存在则自动创建
cur=db.cursor()#获取光标,对数据库的操作一般要通过光标
sql="UPDATE students SET birthday='2001-06-28' WHERE name='钱六'"
#将钱六的生日改为2001-06-28,没有WHERE限制条件,则会更改所有
cur.execute(sql)
db.commit()#落实对数据库的修改,真正地写入数据库,有写入操作时一定要写!!!
cur.close()#关闭光标
db.close()#关闭数据库
import sqlite3
db=sqlite3.connect("F:/tmp/test.db")#连接数据库,若不存在则自动创建
cur=db.cursor()#获取光标,对数据库的操作一般要通过光标
sql="DELETE FROM students WHERE age<18"#删除数据库中年龄小于18的人
cur.execute(sql)
db.commit()#落实对数据库的修改,真正地写入数据库,有写入操作时一定要写!!!
cur.close()#关闭光标
db.close()#关闭数据库
(4)数据库二进制字段处理
import sqlite3
f=open('F:/tmp/picture.jpg','rb')#以二进制的形式打开文件
img=f.read()#将图片的二进制信息存入img
f.close()
db=sqlite3.connect("F:/tmp/test.db")#连接数据库,若不存在则自动创建
cur=db.cursor()#获取光标,对数据库的操作一般要通过光标
sql="UPDATE students SET picture=? WHERE name='小魏'"
cur.execute(sql,(img,))#设置小魏的照片,img对应于?
db.commit()#落实对数据库的修改,真正地写入数据库,有写入操作时一定要写!!!
cur.close()#关闭光标
db.close()#关闭数据库
import sqlite3
import requests#用于访问网络资源
imgUrl="https://gss0.baidu.com/94o3dSag_xI4khGko9WTAnF6hhy/zhidao/pic/item/43a7d933c895d14345aa24687df082025baf0799.jpg"#从网络获得照片
imgStream=requests.get(imgUrl,stream=True)#将图片的二进制数据存到imgStream,该句格式如此,记住就好
db=sqlite3.connect("F:/tmp/test.db")#连接数据库,若不存在则自动创建
cur=db.cursor()#获取光标,对数据库的操作一般要通过光标
sql="UPDATE students SET picture=? WHERE name='张三'"
cur.execute(sql,(imgStream.content,))#设置张三的照片,imgStream.content对应于?
db.commit()#落实对数据库的修改,真正地写入数据库,有写入操作时一定要写!!!
cur.close()#关闭光标
db.close()#关闭数据库
九.正则表达式
1.正则表达式的概念
正则表达式是某些字符有特殊含义的字符串,可以用相关函数用来判断其他字符串是否能与正则表达式进行匹配
正则表达式中的功能字符:\d等不是转义字符,都是两个字符
#(1). :可以匹配除\n外的任何字符,如'a.b'匹配'acb','a(b'等
#(2)*:量词,表示左边的字符可以出现0次或任意多次,如'a*b'匹配'b','aaaab'等
#(3)?:量词,表示左边的字符必须出现1次或0次,如'a?b'匹配'ab','b'
#(4)+:量词,表示左边的字符必须出现1次或更多次,如'a?b'匹配'ab','aab'等
#(5){m}:量词,表示左边的字符必须且只能出现m次,如'a{2}b'匹配'aab'
#(6){m,n}:量词,表示左边的字符必须出现至少m次,至多n次,{m,}代表没有上限
#(7)\d:表示一个数字字符
#(8)\D:表示一个非数字字符
#(9)\s:表示一个空白字符,如空格,\n,\t,\r等
#(10)\S:表示一个非空白字符
#(11)\w:表示一个单词字符,包含汉字,数字,字母,下划线或其他语言文字
#(12)\W:表示一个非单词字符
#(13)|:A|B表示能匹配A或能匹配B算匹配
正则表达式中的特殊字符:. + ? * ( ) [ ] { } ^ \ $,如果要在正则表达式中表示这几个字符本身,应该在前面加\
2.字符范围和量词
#(1)[abc]:匹配a,b,c三个字符之一,如's[abc]t'匹配'sat','sbt','sct'
#(2)[a-zA-Z]:匹配任一英文字母
#(3)[\da-z\?]:匹配一个数字或一个小写英文字母或?
#(4)[^abc]:匹配一个非a,b,c的字符
#(5)[^a-f0-3]:匹配一个不是a-f且不是0-3的字符
#(6)[\u4e00-\u9fa5]:表示一个汉字,汉字的unicode编码范围是4e00-9fa5,\u表示16进制
字符的复合:
#(1).+:匹配任意长度不为0且不含\n的字符串
#(2).*:匹配任意不含\n的字符串
#(3)[\dac]+:匹配长度不为0的由数字或a,c构成的字符串
#(4)\w{5}:匹配长度为5的由单词字符构成的字符串
正则表达式示例:
#[1-9]\d*:正整数,正整数第一个数字一定是1-9
#-?[1-9]\d*|0:整数,-?表示-可有可无,|0或上0的情况
3.正则表达式的函数
使用正则表达式要import re
(1)re.match(pattern,string,flags=0):从string的起始位匹配一个模式pattern,flags标志位用于控制模式串的匹配方式,如果匹配的上则返回一个匹配对象,否则返回None
import re
def match(pattern,string):
x=re.match(pattern,string)
if x!=None:
print(x.group())#匹配对象有函数group用于返回匹配上的字符串
else:
print("None")
match("a c","a cbcd")#a c
match("abc","kabc")#None,从起始位置开始匹配,匹配不上
match("a\tb*c","a\tbbbbcabc")#a bbbbc
(2)re.search(pattern,string,flags=0):查找字符串中第一个可以匹配成功的子串,查找成功返回匹配对象,否则返回None
import re
def search(pattern,string):
x=re.search(pattern,string)
if x!=None:
print(x.group(),x.span())#匹配对象有函数group用于返回匹配上的字符串,x.span()表示子串的起止位置
else:
print("None")
search("abc","kabc")#abc (1,4),(1,4)代表下标1-3
search("[1-9]\d+","ab1234cd")#1234 (2,6)
(3)re.findall(pattern,string,flags=0):查找字符串中所有可以匹配成功的子串,返回一个列表,如果匹配失败则返回空表
import re
print(re.findall("\d+","123 abc 456 def"))#['123','456']
print(re.findall("[a-zA-Z]+","A dog has 4 legs"))#['A', 'dog', 'has', 'legs']
print(re.findall("aaa","abaaaa"))#['aaa']#非重叠查找
(4)re.finditer(pattern,string,flags=0):查找字符串中所有可以匹配成功的子串,返回一个序列,序列中的每个元素都是一个匹配对象
4.边界符号
边界符号本身不与任何字符匹配
#\A:表示字符串的左边界,即要求从此往左边不能有任何字符
#\Z:表示字符串的右边界,即要求从此往右边不能有任何字符
#^:与\A相同,但在多行匹配模式下还可以表示一行文字的左边界
#$:与\Z相同,但在多行匹配模式下还可以表示一行文字的右边界
#\b:表示此处是单词的左边界或右边界,即不可是单词字符,在正则表达式中\b是两个字符,但是python字符串中\b看作一个字符,因此字符串中,应写成\\b,或者在字符串前加r取消\的转义
#\B:表示此处不是单词的左边界或右边界,即必须是单词字符
import re
def search(pattern,string):
x=re.search(pattern,string)
if x!=None:
print(x.group(),x.span())#匹配对象有函数group用于返回匹配上的字符串,x.span()表示子串的起止位置
else:
print("None")
pt="ka\\b.*"
search(pt,"ka")#ka (0,2),a的右边不是单词字符,可以匹配
search(pt,"kab")#None,a的右边是单词字符,匹配失败
5.分组
括号中的一个表达式就是分组,多个分组按照左括号,从左到右从1开始编号
import re
m="(((ab*)c)d)e"
r=re.match(m,"abcdefg")
print(r.group(0))#abcde,group(0)等价于group()
print(r.group(1))#abcd输出第一个分组
print(r.group(2))#abc
print(r.group(3))#ab
print(r.groups())#('abcd','abc','ab'),groups()返回一个元组,元组各元素是一个分组
在分组的右边可以通过分组的编号引用该分组所匹配的子串
import re
m=r'(((ab*)c)d)e\3'#r说明取消\的转义,\3要求ab*cde后面跟着3号分组在本次匹配中匹配上的子串
r=re.search(m,"abbbcdeabbb")#3号分组对应的子串为abbb,因此只有abbbcde后面跟上abbb才能匹配成功
print(r.groups())#('abbbcd', 'abbbc', 'abbb')
分组作为一个整体,后面可以跟量词,且不一定需要匹配相同的字符串
import re
m='(((ab*)+c)d)e'#说明3号分组可以在相应位置出现多次
r=re.search(m,"abababcde")
print(r.groups())#('abababcd', 'abababc', 'ab')
r=re.search(m,"abacde")#a也算是ab*的重复出现,因为*允许b出现0次
print(r.groups())#('abacd', 'abac', 'a'),3号分组进行了两次匹配,第一次匹配上了ab,第二次匹配上了a,取最后一次匹配结果
当正则表达式中没有分组时,re.findall返回所有匹配子串构成的列表
当正则表达式有且仅有一个分组时,re.findall返回的是一个子串的列表,每个元素是一个匹配子串中分组对应的内容
当正则表达式中有超过一个分组时,re.findall返回的是一个元组的列表,元组中的每个元素依次是各个分组的内容
import re
m='[a-z]+(\d+)[a-z]+'#匹配两边被字母夹着的数
x=re.findall(m,"abc12def asd34bdf")
print(x)#['12','34']
6.|的用法
|表示或,如果没有放在分组中,|的起作用范围是直到整个正则表达式开头或结尾的另一个”|“
|从左到右短路匹配,当匹配到左边的后不会再匹配右边
import re
pt="aa|aab"
x=re.findall(pt,"aab123cdaaaab")#短路匹配
print(x)#['aa', 'aa', 'aa']
|也可以用在分组中,起作用的范围就仅限于分组
7.贪婪模式和懒惰模式
(1)贪婪模式
量词+,*,?,{m,n}都默认匹配尽可能长的子串,存在很明显的弊端
(2)懒惰模式
即为非贪婪模式,在量词+,*,?,{m,n}后面加上?则匹配尽可能短的子串
import re
m1="a.*b"#贪婪模式
m2="a.*?b"#懒惰模式
r1=re.findall(m1,"abcdadbb")
print(r1)#['abcdadbb']
r2=re.findall(m2,"abcdadbb")
print(r2)#['ab', 'adb']
8.匹配对象的函数
import re
m=re.match(r"(\w+) (\w+)(.)","hello world!ss")#匹配两个单词加一个字符
print(m.string)#hello world!ss,string返回用来做匹配的整个母串
print(m.lastindex)#3,lastindex返回在整个正则表达式中最后一个被匹配上的分组的编号
print(m.group(0,1,2,3))#('hello world!', 'hello', 'world', '!')
print(m.groups())#('hello', 'world', '!')
print(m.start(2))#6,start返回第二个分组起始位置在母串中的下标
print(m.end(2))#11,end返回第二个分组终止位置在母串中的下标+1
print(m.span(2))#(6,11)
十.玩转Python生态
1.用datatime库处理日期、时间
处理日期:
import datetime#导入datatime模块
dtBirth=datetime.date(2002,4,16)#创建日期对象,日期为2002年4月16日
print(dtBirth.weekday())#2,输出dtBirth对应的日期是星期几,0表示星期一
dtNow=datetime.date.today()#取今天日期
print(dtNow>dtBirth)#True,日期可以比大小
life=dtNow-dtBirth#取两个日期的时间差
print(life.days,life.total_seconds())#输出天数以及对应的秒数
delta=datetime.timedelta(days=-10)#构建时间差对象,时间差为-10天
newDate=dtNow+delta#新日期为当前时间往前推十天
print(newDate.year,newDate.month,newDate.day)#输出年月日
print(newDate.strftime(r'%m/%d/%Y'))#strftime用于控制输出格式,%m输出两位的月,%d输出两位的日,%Y输出四位的年,输出字符串
newDate=datetime.datetime.strptime("2022.1.24","%Y.%m.%d")#将字符串转为日期对象
print(newDate.strftime("%Y %m %d"))#将日期对象转为字符串
处理时刻:
import datetime
tm=datetime.datetime.now()#取当前时刻精确到微秒
print(tm.year,tm.month,tm.day,tm.hour,tm.minute,tm.second,tm.microsecond)#输出当前时刻
tm=datetime.datetime(2022,1,24,19,23,10,0)#构建时刻对象,时刻为2022年1月24日19时23分10秒0微妙
print(tm.strftime("%Y%m%d: %H:%M:%S"))#20220124: 19:23:10,strftime也可以将时刻转为字符串
print(tm.strftime("%Y%m%d: %I:%M:%S %p"))#20220124: 07:23:10 PM,也可以按照12小时制输出,%p用于输出AM/PM
tm2=datetime.datetime.strptime("2002.01.24 07:23:10","%Y.%m.%d %H:%M:%S")#由字符串生成一个时间对象
delta=tm-tm2#求两个时间的时间差,delta即为一个时间差对象
print(delta.days,delta.seconds,delta.total_seconds())#7305 43200 631195200.0
#时间差是7305天零43200秒,总计631195200秒
2.用random库处理随机事务
import random
print(random.random())#0.6122495917345335,生成一个介于0和1之间的随机数
print(random.uniform(1.2,7.8))#6.9827624080681465,生成一个在[1.2,7.8]之间的随机数
print(random.randint(-20,70))#-13,生成一个在[-20,70]间的随机整数
print(random.randrange(2,20,3))#11,按步长为3生成一个[2,20)间的随机整数
print(random.choice([1,2,3,'Jack','Mike',4,5]))#4,在列表中随机抽取一个元素
lst=[1,2,3,4,5]
random.shuffle(lst)#随机排列lst
print(lst)#[3, 1, 2, 5, 4]
print(random.sample(lst,3))#[4,2,3],从lst中随机取出三个元素
设置随机数种子:如果没有设置则是按照系统时间作为随机数种子,随机数种子设定后每次随机结果都是唯一的
import random
random.seed(2)#设置随机数种子为2,随机数种子可以任意,既可以为数字也可以为字符串等
print(random.randint(1,100))#8,每次随机结果都为8
random库应用实例:
#实现四人玩牌的发牌模拟
import random
cards=[str(i) for i in range(2,11)]
cards.extend(list("JQKA"))#设置好牌列表
allCards=[]#一副牌
for s in "♠♣♥♦":
for c in cards:
allCards.append(s+c)#将52张牌放入整副牌中
random.shuffle(allCards)#随机打乱整副牌
for i in range(4):
onePlayer=allCards[i::4]#每个玩家每隔三张取一张牌
onePlayer.sort()#按照花色对牌进行排序
print(onePlayer)
#输出示例:
# ['♠3', '♠6', '♠8', '♣4', '♣6', '♣7', '♥2', '♥6', '♥A', '♥K', '♦10', '♦A', '♦Q']
# ['♠10', '♠5', '♠7', '♠J', '♣2', '♣9', '♥3', '♥4', '♥8', '♥9', '♦2', '♦8', '♦9']
# ['♠4', '♠9', '♠A', '♣10', '♣3', '♣5', '♣K', '♣Q', '♥5', '♥7', '♥Q', '♦6', '♦K']
# ['♠2', '♠K', '♠Q', '♣8', '♣A', '♣J', '♥10', '♥J', '♦3', '♦4', '♦5', '♦7', '♦J']
3.用jieba库进行分词和中文词频统计
import jieba#导入分词库
jieba.setLogLevel(jieba.logging.INFO)#避免jieba库报错
s="我们热爱中华人民共和国"
lst=jieba.lcut(s)#对s进行分词并转成一个列表,默认用精确模式分词,分词的结果正好可以拼成原文
print(lst)#['我们', '热爱', '中华人民共和国']
lst=jieba.lcut(s,cut_all=True)#全模式分词,输出所有可能的词
print(lst)#['我们', '热爱', '中华', '中华人民', '中华人民共和国', '华人', '人民', '人民共和国', '共和', '共和国']
lst=jieba.lcut_for_search(s)#搜索引擎模式分词,会对一些比较长的词进行细分
print(lst)#['我们', '热爱', '中华', '华人', '人民', '共和', '共和国', '中华人民共和国']
s="拼多多是个网站"
lst=jieba.lcut(s)#在jieba库中并未收录"拼多多"这个词,所以会拆分开
print(lst)#['拼', '多多', '是', '个', '网站']
jieba.add_word("拼多多")#向字典中加入拼多多这个词
lst=jieba.lcut(s)
print(lst)#['拼多多', '是', '个', '网站']
不仅可以将一个词加入jieba的字典,也可以将一个文件中的词加入jieba的字典
import jieba#导入分词库
jieba.setLogLevel(jieba.logging.INFO)#避免jieba库报错
s="关山口男子职业技术学院和五道口职业技术学院"
print(jieba.lcut(s))#['关山', '口', '男子', '职业', '技术', '学院', '和', '五道口', '职业', '技术', '学院']
jieba.load_userdict("F:/tmp/test1.txt")#文件的内容为:关山口男子职业技术学院 五道口职业技术学院
print(jieba.lcut(s))#['关山口男子职业技术学院', '和', '五道口职业技术学院']
4.用openpyxl库处理excel文档
(1)用openpyxl库读取excel文档
import openpyxl as pxl#以下代码用pxl代替openpyxl
book=pxl.load_workbook("F:/tmp/book.xlsx")#打开excel文档
sheet=book.worksheets[0]#取第0张工作表,也可以写成sheet=book.active#取活跃的工作表,缺省的就是第0张工作表
#worksheets是工作表构成的列表
print(sheet.title)#打印工作表名称
print(sheet.min_row,sheet.max_row)#输出工作表的最小有效行号和最大有效行号
print(sheet.min_column,sheet.max_column)#输出工作表的最小有效列号和最大有效列号
for row in sheet.rows:#按行遍历整个工作表,从第1行到第sheet.max_row行
for cell in row:#遍历一行的每个单元格
print(cell.value)#cell.value是单元格的值,空单元格的值是None
for cell in sheet['B']:#遍历名为'B'的那一列
print(cell.value)
for cell in sheet[3]:#遍历第三行
print(cell.value,type(cell.value),cell.coordinate,cell.col_idx,cell.number_format)
#type()返回单元格值的类型;cell.coordinate是单元格的坐标,是一个字符串;cell.col_idx是单元格列号,是一个整数,从1开始算
#cell.number_format是单元格数据的显示格式,通常为"General"
import openpyxl as pxl#以下代码用pxl代替openpyxl
book=pxl.load_workbook("F:/tmp/book.xlsx")
sheet=book.worksheets[0]
print(pxl.utils.get_column_letter(5))#E,根据列号求列名
print(pxl.utils.column_index_from_string('D'))#4,根据列名求列号
print(pxl.utils.column_index_from_string('AC'))#29
colRange=sheet['C:F']#取sheet的第C列到第F列,包含F列
for col in colRange:#遍历C-F列
for cell in col:
print(cell.value)
rowRange=sheet[2:9]#取sheet的第2行到第9行,包含第9行
for row in rowRange:#遍历2-9行
for cell in row:
print(cell.value)
print(sheet['C9'].value)#输出'C9'单元格的值
print(sheet.cell(row=8,column=4).value)#输出第8行第4列的单元格的值
有时候单元格中的内容是公式,希望打开文档的时候自动计算公式的值,则可进行如下操作:
import openpyxl as pxl
book=pxl.pxl.load_workbook("F:/tmp/book.xlsx",data_only=True)#data_only=True使得公式的值自动计算
(2)用openpyxl库创建excel文档
import openpyxl
import datetime
book=openpyxl.Workbook()#在内存中创建一个Excel文档,但是还未存到硬盘中,注意W为大写
sheet=book.active#取第0张工作表
sheet.title="sample1"#工作表取名为sample1
dataRows=((10,20,30,40),(100,200,'=sum(A1:B2)'),[],['1000',datetime.datetime.now(),'OK'])
#准备添加进excel文档的数据信息,'=sum(A1:B2)'为求和公式,注意1000是字符串形式,在excel文档中对应的单元格左上角会有绿色小三角
for row in dataRows:
sheet.append(row)#在工作表中添加一行,要求row是一个列表或元组
sheet.column_dimensions['B'].width=len(str(sheet['B4'].value))
#datetime.datetime.now()为一个较长的字符串,为了保证正常显示,则需要设置好B列的宽度
sheet.row_dimensions[2].height=48#设置第二行高度为48 points
sheet['E1'].value='=sum(A1:D1)'#将E1单元格的值设置为公式
sheet['E2'].value=0.125
sheet['E2'].number_format="0.00%"#设置单元格显示格式为百分比形式
sheet2=book.create_sheet("sample0",0)#添加一个名为sample0的工作表,且将之设为第0张工作表,原来的第0张工作表变为第1张
sheet3=book.copy_worksheet(sheet)#在最右侧添加一张新的工作表,其为sheet的拷贝
book.remove_sheet(book["sample0"])#删除名为sample0的工作表
book.save("F:/tmp/sample.xlsx")#保存文件
(3)用openpyxl库设定excel文档单元格样式
import openpyxl
from openpyxl.styles import Font,colors,PatternFill,Alignment,Side,Border#引入openpyxl.styles中的一些包
book=openpyxl.Workbook()#在内存中创建一个Excel文档,但是还未存到硬盘中,注意W为大写
sheet=book.active#取第0张工作表
for i in range(4):
sheet.append([i*5+j for j in range(5)])
side=Side(style="thin")#边线类型,还可以是thick,medium,dotted等
border=Border(left=side,right=side,top=side,bottom=side)#边框类型
for row in sheet.rows:
for cell in row:
cell.border=border
sheet['A1'].fill=PatternFill(patterntype='solid',start_color=colors.GREEN)
#单元格的fill代表填充样式,solid代表背景纯色填充,单元格底色设置为绿色
a1=sheet['A1']
italicRedFont=Font(size=18,name='Times New Roman',bold=True,color=colors.RED)
#创建一个Font对象,字体大小为18,字体为Times New Roman,bold代表是否为粗体,color代表字体颜色
a1.font=italicRedFont#设置单元格的字体
sheet['A2'].font=a1.font.copy(italic=True)#将A2单元格的格式设置为和A1一样,但是字体是斜体,italic代表斜体
sheet.merge_cells('C2:D3')#从C2到D3合并为一个单元格,此后该单元格名为C2
sheet['C2'].alignment=Alignment(horizontal='left',vertical='center')
#horizontal代表水平对齐格式,vertical代表垂直对齐格式,将C2设置为水平左对齐和垂直居中
book.save("F:/tmp/style.xlsx")
4.用Pillow处理图像
(1)图像基本常识:
图像由像素构成:屏幕上每个像素点由三个距离非常近的点构成,分别显示红绿蓝三种颜色,每个像素可以由一个元组表示(r,g,b), r,g,b通常是不大于255的整数,分别表示红绿蓝三原色的深浅程度
图像模式:
①RGB:一个像素有红绿蓝三个分量
②RGBA:一个像素有红绿蓝三个分量以及透明分量
③CYMK:一个像素有青色(Cyan),洋红色(Magenta),黄色(Yellow),黑色(K代表黑)四个分量构成,每个像素用元组(c,y,m,k)表示,对应于彩色打印机或者印刷机的四种颜色墨水
L:黑白图像,像素就是一个整数,代表灰度
(2)图像的基本操作:
①图像的缩放:
from PIL import Image#导入Image类进行图像处理
img=Image.open("F:/tmp/HUST.jpg")#将图像文件载入对象img
w,h=img.size#获取图像的宽和高,单位为像素,img.size是一个元组
print(w,h)
newSize=(w//2,h//2)#生成一个新的图像尺寸,//为了保留整数
newImg=img.resize(newSize)#得到一张原图像一半大小(1/4)的新图像,resize返回一张新图像
newImg.save("F:/tmp/half_HUST.jpg")#保存新图像文件
newImg.thumbnail((128,128))#变成宽高各128像素的缩略图
newImg.save("F:/tmp/128_HUST.png","PNG")#保存新图像为png文件
newImg.show()#显示图像文件
②图像的旋转、翻转和滤镜效果:
from PIL import Image#导入Image类进行图像处理
from PIL import ImageFilter#导入ImageFilter实现滤镜效果
img=Image.open("F:/tmp/HUST.jpg")#将图像文件载入对象img
print(img.format,img.mode)#JPEG RGB,format为图像的格式,mode为图像的模式
newImg=img.rotate(90,expand=True)#图像逆时针旋转90°,expand=True说明图像的长宽跟随旋转变化
newImg.show()
newImg=img.transpose(Image.FLIP_LEFT_RIGHT)#左右翻转
newImg.show()
newImg=img.transpose(Image.FLIP_TOP_BOTTOM)#上下翻转
newImg.show()
newImg=img.filter(ImageFilter.BLUR)#模糊效果
newImg.show()
#ImageFilter.CONTOUR,轮廓效果
#ImageFilter.EDGE_ENHANCE,边缘增强
#ImageFilter.EMBOSS,浮雕
#ImageFilter.SMOOTH,平滑
#ImageFilter.SHARPEN,锐化
③图像的裁剪:
#以裁剪九宫格图像为例,先将图片拆分成九张图,再将九张图组合成一张九宫图
from PIL import Image#导入Image类进行图像处理
img=Image.open("F:/tmp/HUST.jpg")#将图像文件载入对象img
w,h=img.size[0]//3,img.size[1]//3#获取九宫格图片宽与高
gap=10#九宫图中相邻两幅子图间的空白宽10像素
newImg=Image.new("RGB",(w*3+gap*2,h*3+gap*2),"white")
#生成一幅新的图,图片模式为RGB,设置好宽高为对应九宫图宽高,新图的底色为白色
for i in range(3):
for j in range(3):
clipImg=img.crop((j*w,i*h,(j+1)*w,(i+1)*h))#crop用于进行图片的切割,4个元素对应所要切割部分左上角和右下角的坐标
newImg.paste(clipImg,(j*(w+gap),i*(h+gap)))#将clipImg粘贴到newImg上,坐标为粘贴左上角的坐标
newImg.save("F:/tmp/HUST_9.jpg")
newImg.show()
④图像素描化:
from PIL import Image#导入Image类进行图像处理
def makeSketch(img,threshold):
#进行图像img素描化处理,threshold为阈值,当黑白图片相邻两个像素的灰度差值超过阈值,则认为此处为轮廓
w,h=img.size
img=img.convert('L')#图像转换成灰度模式,convert用于转换图像的模式
pix=img.load()#获取像素矩阵
for x in range(w-1):#遍历像素矩阵
for y in range(h-1):
if abs(pix[x,y]-pix[x+1,y+1])>=threshold:#取一个像素和它右下角像素点作为相邻
pix[x,y]=0#变为黑色
else:
pix[x,y]=255#变为白色
return img
img=Image.open("F:/tmp/HUST.jpg")#将图像文件载入对象img
img=makeSketch(img,15)#取15作为阈值
img.show()
⑤为图像添加水印:
原理:在将一个图像粘贴到另一个图像上时,会用到paste函数,paste函数还有一个参数mask称为“掩膜”指定img的每个像素粘贴过去的透明度,如果透明度为0则完全透明,如果透明度为255则完全遮盖原图像的像素
mask本质上是一个模式为“L”的图片即一个Image对象
from PIL import Image#导入Image类进行图像处理
def getMask(img,isTransparent,alpha):
#返回由img变出来的掩膜
#isTransparent为一个函数用来指明img中什么样的像素应该是完全透明的,alpha为透明度,指明不为完全透明的像素的透明度
if img.mode!="RGBA":
img=img.convert("RGBA")#将图像模式转为RGBA
w,h=img.size
pixels=img.load()#获取像素矩阵
for x in range(w):
for y in range(h):
p=pixels[x,y]#p是一个四元组(r,g,b,a)
if isTransparent(p[0],p[1],p[2]):#判断p是否应变成透明像素,三个参数对应像素点的红绿蓝分量
pixels[x,y]=(p[0],p[1],p[2],0)
else:
pixels[x,y]=(p[0],p[1],p[2],alpha)
r,g,b,a=img.split()#分理出img中的四个分量,a就是掩膜
return a
img=Image.open("F:/tmp/logo.png")#将图像文件载入对象img,水印图像
img=img.resize((img.size[0]*10,img.size[1]*10))#适当扩大图像
msk=getMask(img,lambda r,g,b:r>245 and g>245 and b>245,130)#白色点的r,g,b都为255
imgSrc=Image.open("F:/tmp/HUST.jpg")#将图像文件载入对象imgSrc,目标图像
imgSrc.paste(img,(imgSrc.size[0]-img.size[0]-30,imgSrc.size[1]-img.size[1]-30),mask=msk)
#粘贴透明图像img到imgSrc的合适位置
imgSrc.show()
十一.数据分析和展示
1.numpy库的使用
numpy是一个多维数组库,创建多维数组很方便,可以代替多维列表,速度比多维列表快,支持向量和矩阵的各种数学运算,所有元素类型必须相同
(1)用numpy库创建数组
import numpy as np#以下np即为numpy
print(np.array([1,2,3]))#[1 2 3],以列表[1,2,3]创建数组
print(np.arange(1,9,2))#[1 3 5 7],在区间[1,9)中从1开始以步长为2创建一个数组
print(np.linspace(1,10,4))
#[ 1. 4. 7. 10.],在区间[1,10]以步长为4取数,即对[1,10]三等分,取等分点和1,10构成数组,注意取出的数都为小数
print(np.random.randint(10,20,[2,3]))#从[10,20)中随机取整数,构成2行3列的二维数组
#[[19 15 11]
# [13 17 10]]
print(np.random.randint(10,20,5))#[15 16 16 14 15],从[10,20)中随机取整数,构成5个元素的一维数组
a=np.zeros(3)#创建一个包含三个小数0的数组
print(a)#[0. 0. 0.]
print(list(a))#[0.0, 0.0, 0.0]
a=np.zeros((2,3),dtype=int)#创建一个2行3列,元素都是整数0的数组
print(a)
#[[0 0 0]
# [0 0 0]]
(2)numpy常用的属性与函数
import numpy as np
b=np.array([i for i in range(12)])
#b是[ 0 1 2 3 4 5 6 7 8 9 10 11]
a=b.reshape((3,4))#将数组转成3行4列的数组赋给a,b不变
#[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(len(a))#3,a有3行
print(a.size)#12,输出a中的元素个数
print(a.ndim)#2,输出a是几维数组
print(a.shape)#(3,4),输出a是几行几列的,输出一个元组
print(a.dtype)#int32,输出a中的元素类型是32bit的整数
L=a.tolist()#转换成列表,a不变
print(L)#[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]]
L=list(a)#最外层维转换成列表,如果是多维数组则内部仍为数组
print(L)#[array([0, 1, 2, 3]), array([4, 5, 6, 7]), array([ 8, 9, 10, 11])]
b=a.flatten()#转换成一维数组
print(b)#[ 0 1 2 3 4 5 6 7 8 9 10 11]
(3)numpy数组元素增删
numpy数组一旦生成,则不能增删元素,此处的增删指的是增删之后生成一个新数组,原数组保持不变
numpy增添数组元素:
import numpy as np
a=np.array((1,2,3))#a为数组[1 2 3]
b=np.append(a,10)#向a中插入10得到新数组赋给b,a不变
#append(x,y)即将y中元素插入到数组x中去
print(a,b)#[1 2 3] [ 1 2 3 10]
c=np.zeros((2,3),dtype=int)#c为2行3列的元素都为整数0的二维数组
print(np.append(a,c))#[1 2 3 0 0 0 0 0 0]
print(np.concatenate((a,[10,20],a)))#[ 1 2 3 10 20 1 2 3]
#concatenate将元组中元素连接起来得到一个新的数组,原数组不变
d=np.concatenate((c,np.array([[10,20,30]])))#c拼接1行得到新数组
print(d)
#[[ 0 0 0]
# [ 0 0 0]
# [10 20 30]]
e=np.concatenate((c,np.array([[1,2],[10,20]])),axis=1)#c第一行拼接[1,2],第二行拼接[10,20]得到新数组
#axis指明拼接发生在行上面还是发生在列上面,axis缺省为0,拼接发生在行上面,axis=1时拼接发生在列上面
print(e)
#[[ 0 0 0 1 2]
# [ 0 0 0 10 20]]
numpy删除数组元素:
import numpy as np
a=np.array((1,2,3,4))
b=np.delete(a,1)#删除a中下标为1的元素得到新数组
print(a,b)#[1 2 3 4] [1 3 4]
b=np.array([i for i in range(12)]).reshape((3,4))
c=np.delete(b,1,axis=0)#删除b的第一行得到新数组
print(c)
#[[ 0 1 2 3]
# [ 8 9 10 11]]
d=np.delete(b,1,axis=1)#删除b的第一列得到新数组
print(d)
#[[ 0 2 3]
# [ 4 6 7]
# [ 8 10 11]]
e=np.delete(b,[0,1],axis=0)#删除b的第0行和第1行得到新数组
print(e)
#[[ 8 9 10 11]]
(4)在numpy数组中查找元素
import numpy as np
a=np.array((1,2,3,5,3,4))
pos=np.argwhere(a==3)#在pos中查找元素3,返回值为一个数组,数组中存储着查找到的元素下标
print(pos)
#[[2]
# [4]]
a=np.array([[1,2,3],[4,5,2]])
print(2 in a)#True
pos=np.argwhere(a==2)#pos为一个二维数组,存储着2的坐标[行号,列号]
print(pos)
#[[0 1]
# [1 2]]
b=a[a>2]#抽取a中大于2的元素构成一个一维数组
print(b)#[3 4 5]
a[a>2]=-1#使a中大于2的元素值变为-1
print(a)
#[[ 1 2 -1]
# [-1 -1 2]]
(5)numpy数组的数学运算
import numpy as np
a=np.array((1,2,3,4))
b=a+1#得到一个新数组,该数组中每个元素都是a中的元素+1
print(b)#[2 3 4 5]
print(a*b)#[2 6 12 20],a,b中对应元素相乘
print(a+b)#[3 5 7 9],a,b中对应元素相加
c=np.sqrt(a*10)#a*10是[10 20 30 40],将其每个元素开方后赋给新数组c
print(c)#[3.16227766 4.47213595 5.47722558 6.32455532]
(6)numpy数组的切片
不同于列表的切片,numpy数组的切片是“视图”,即为原数组的一部分,而非原数组一部分的拷贝,切片改变原数组也改变
import numpy as np
a=np.arange(8)#[0 1 2 3 4 5 6 7]
b=a[3:6]#b是a的一部分
print(b)#[3 4 5]
c=np.copy(a[3:6])#c是a一部分的拷贝
b[0]=100
print(a)#[ 0 1 2 100 4 5 6 7]
print(c)#[3 4 5]
a=np.array([i for i in range(1,17)]).reshape((4,4))
b=a[1:3,1:4]#行从第1行取到第2行,列从第1列取到第3列
print(b)
#[[ 6 7 8]
# [10 11 12]]
2.数据分析库pandas
pandas的核心功能是在二维表格上做各种操作,需要numpy库的支持,在openpyxl库的支持下还可以读取excel文档
pandas中最为关键的类是DataFrame,用于表示二维表格
(1)pandas的重要类Series
Series为一维表格,每个元素带有标签与下标,类似于列表和字典的结合
import pandas as pd
s=pd.Series(data=[80,90,100],index=['语文','数学','英语'])
#创建一个一维表格,data为表格中的数据,index为每一个表格的标签
for x in s:
print(x,end=" ")#80 90 100,输出表格中的元素
print("")
print(s['语文'],s[1])#80,90,可以用标签和下标进行访问
print(s[0:2]['数学'])#90,切片与列表等切片规则相同,但是注意Series切片也是视图!!!!
print(s['数学':'英语'][1])#100,当用标签做切片时,终点是算在内的
for i in range(len(s.index)):
print(s.index[i],end=" ")#语文 数学 英语
s['体育']=110#与字典相同,在表格末尾添加体育项
s.pop('数学')#与字典相同,删除数学项
s2=s.append(pd.Series(120,index=['政治']))#append不会改变s而是会创建一个新的一维表格,它的功能不是添加而是连接
print(list(s2))#[80,100,110,120]
print(list(s))#[80,100,110]
print(s.sum(),s.min(),s.max(),s.mean(),s.median())
#290 80 110 96.66666666666667 100.0,输出和,最小值,最大值,平均数,中位数
print(s.idxmax(),s.argmax())#'体育',2,输出最大元素的标签与下标
(2)DataFrame的构造和访问
DataFrame是带行列标签的二维表格,它的每一行都是一个Series
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)#输出对齐方面的设置
scores=[['男',108,115,97],['女',115,87,105],['女',100,60,130],['男',112,80,50]]#表格信息
name=['刘一哥','王二姐','张三妹','李四弟']#标签信息
courses=['性别','语文','数学','英语']#列信息
df=pd.DataFrame(data=scores,index=name,columns=courses)#构建二维表格
print(df)
# 性别 语文 数学 英语
# 刘一哥 男 108 115 97
# 王二姐 女 115 87 105
# 张三妹 女 100 60 130
# 李四弟 男 112 80 50
print(df.values[0][1],type(df.values))#108 <class 'numpy.ndarray'>,values部分其实是一个numpy数组
print(list(df.index))#['刘一哥', '王二姐', '张三妹', '李四弟']
print(list(df.columns))#['性别', '语文', '数学', '英语']
print(df.index[2],df.columns[2])#'张三妹' '数学'
s1=df['语文']#s1是一个Series,代表'语文'那一列
print(s1['刘一哥'],s1[0])#108 108
print(df['语文']['刘一哥'])#108,注意访问时一定要保证列索引先写
s2=df.loc['王二姐']#s2是一个Series,代表'王二姐'那一行,注意取行需要加loc
#注意s1和s2都是视图,改变s1和s2,df也会跟着改变
print(list(s2))#['女', 115, 87, 105]
(3)DataFrame的切片、增删和统计
①DataFrame的切片:
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)#输出对齐方面的设置
scores=[['男',108,115,97],['女',115,87,105],['女',100,60,130],['男',112,80,50]]#表格信息
name=['刘一哥','王二姐','张三妹','李四弟']#标签信息
courses=['性别','语文','数学','英语']#列信息
df=pd.DataFrame(data=scores,index=name,columns=courses)#构建二维表格
print(df)
# 性别 语文 数学 英语
# 刘一哥 男 108 115 97
# 王二姐 女 115 87 105
# 张三妹 女 100 60 130
# 李四弟 男 112 80 50
df2=df.iloc[1:3]#iloc为用下标做切片,取1,2两行,没有写列选择器说明所有的列都要取
df2=df.loc['王二姐':'张三妹','性别':'英语']#loc为用标签做切片,取1,2两行,取'性别'列到'英语'列
print(df2)
# 性别 语文 数学 英语
#王二姐 女 115 87 105
#张三妹 女 100 60 130
df3=df.iloc[[1,3],[1,3]]#取1,3行,1,3列
df3=df.loc[['王二姐','李四弟'],['语文','英语']]#取1,3行,1,3列
print(df3)
# 语文 英语
#王二姐 115 105
#李四弟 112 50
②DataFrame的分析统计:
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)#输出对齐方面的设置
scores=[['男',108,115,97],['女',115,87,105],['女',100,60,130],['男',112,80,50]]#表格信息
name=['刘一哥','王二姐','张三妹','李四弟']#标签信息
courses=['性别','语文','数学','英语']#列信息
df=pd.DataFrame(data=scores,index=name,columns=courses)#构建二维表格
print(df)
# 性别 语文 数学 英语
# 刘一哥 男 108 115 97
# 王二姐 女 115 87 105
# 张三妹 女 100 60 130
# 李四弟 男 112 80 50
print(df.T)#df.T是df的转置矩阵
print(df.sort_values('语文',ascending=False))#按语文成绩降序排列,返回一个新的DataFrame,对行进行了重排
#注意sort_values(...inplace=True,axis=1)inplace说明进行原地排序,会改变df,axis=1说明对列进行重排
#性别 语文 数学 英语
#王二姐 女 115 87 105
#李四弟 男 112 80 50
#刘一哥 男 108 115 97
#张三妹 女 100 60 130
print(df.sum()['语文'],df.mean()['数学'],df.median()['英语'],df.min()['语文'])#默认为求列的相应值
#435 85.5 101.0 100语文成绩和,数学平均分,英语中位数,语文最低分
print(df.max(axis=1)['王二姐'])#115,axis=1说明进行列检索,求王二姐的最高分
print(df['语文'].idxmax())#'王二姐',输出语文最高分所在行的标签
print(df['数学'].argmin())#'2',输出数学最低分所在行的行号
print(df.loc[(df['语文']>100)&(df['数学']>=85)])#求切片,行选择器为语文大于100,数学大于85
③DataFrame的修改和增删:
修改和增加:
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)#输出对齐方面的设置
scores=[['男',108,115,97],['女',115,87,105],['女',100,60,130],['男',112,80,50]]#表格信息
name=['刘一哥','王二姐','张三妹','李四弟']#标签信息
courses=['性别','语文','数学','英语']#列信息
df=pd.DataFrame(data=scores,index=name,columns=courses)#构建二维表格
print(df)
# 性别 语文 数学 英语
# 刘一哥 男 108 115 97
# 王二姐 女 115 87 105
# 张三妹 女 100 60 130
# 李四弟 男 112 80 50
df.loc['王二姐','英语']=df.iloc[0,1]=150
#修改王二姐的英语和刘一哥的语文成绩为150
df['物理']=[80,70,90,100]#增添物理列为最后一列
df.insert(1,'体育',[89,77,76,45])#为所有人插入体育成绩到第一列
df.loc['钱五叔']=['男',100,100,100,100,100]#增添钱五叔行到最后一行
df.loc[:,'英语']+=10#为所有人英语加10分,等价于df['英语']+=10
df.columns=['性别','体育','语文','数学','English','物理']#修改列标签
#df.columns[4]='English'#错误,不可单独修改
print(df)
# 性别 体育 语文 数学 English 物理
#刘一哥 男 89 150 115 107 80
#王二姐 女 77 115 87 160 70
#张三妹 女 76 100 60 140 90
#李四弟 男 45 112 80 60 100
#钱五叔 男 100 100 100 110 100
删除:
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)#输出对齐方面的设置
scores=[['男',108,115,97],['女',115,87,105],['女',100,60,130],['男',112,80,50]]#表格信息
name=['刘一哥','王二姐','张三妹','李四弟']#标签信息
courses=['性别','语文','数学','英语']#列信息
df=pd.DataFrame(data=scores,index=name,columns=courses)#构建二维表格
print(df)
# 性别 语文 数学 英语
# 刘一哥 男 108 115 97
# 王二姐 女 115 87 105
# 张三妹 女 100 60 130
# 李四弟 男 112 80 50
df.drop(['英语'],axis=1,inplace=True)#只删除一列时,可以不加[]
#删除英语那一列,axis=1说明删除列,inplace=True说明在df本身进行修改而不产生新的DataFrame
df.drop('王二姐',axis=0,inplace=True)#删除王二姐那一行
df.drop([df.index[i] for i in range(2)],axis=0,inplace=True)#删除0,1行
print(df)
#性别 语文 数学
#李四弟 男 112 80
(4)用pandas库读取excel和csv文档
需要依赖于openpyxl库
①用pandas读excel文档:读取的每张工作表都是一个DataFrame
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)#输出对齐方面的设置
dt=pd.read_excel("F:/tmp/book.xlsx",sheet_name=['sheet1',1],index_col=0)
#sheet_name为表名,[]中的是需要读取的表,既可以用表名读取如'sheet1',也可以用表的编号读取如1,index_col来说明用哪一列作为标签,index_col=0说明取第0列作为标签
#函数返回值是一个字典,字典元素的键是表名,值是DataFrame
df=dt['sheet1']#dt是字典,df是Dataframe
print(df.iloc[0,0],df.loc[14,'课程名称'],df['课程名称'][15])#Verilog语言 Verilog语言 机器学习
#三种访问DataFrame单元格的方式
print(df)#空单元格显示NaN
print(pd.isnull(df.iloc[0,0]))#False,isnull用于判断某个单元格是不是空
df.fillna(0,inplace=True)#将NaN替换成0,fillna用于将NaN替换成其他的值,inplace=True说明在df本身进行修改
②用pandas写excel文档
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)#输出对齐方面的设置
scores=[['男',108,115,97],['女',115,87,105],['女',100,60,130],['男',112,80,50]]#表格信息
name=['刘一哥','王二姐','张三妹','李四弟']#标签信息
courses=['性别','语文','数学','英语']#列信息
df=pd.DataFrame(data=scores,index=name,columns=courses)#构建二维表格
print(df)
# 性别 语文 数学 英语
# 刘一哥 男 108 115 97
# 王二姐 女 115 87 105
# 张三妹 女 100 60 130
# 李四弟 男 112 80 50
writer=pd.ExcelWriter("F:/tmp/new.xlsx")#创建ExcelWriter对象
df.to_excel(writer,sheet_name="S1")#将df写入excel
df['语文'].to_excel(writer,sheet_name="S2")#只写入一列
writer.save()#保存excel文档
3.用matplotlib进行数据展示
在此感慨:清华镜像源yyds!!!
(1)绘制直方图
import matplotlib.pyplot as plt#引入matplotlib包中的pyplot
from matplotlib import rcParams
rcParams['font.family']=rcParams['font.sans-serif']='SimHei'
#设置中文支持,中文字体为简体黑体,当不需要中文时则不需要这两行
ax=plt.figure().add_subplot()#建图,获取子图对象ax
#plt.figure()创建了一个窗口对象,add_subplot()在窗口对象上创建一个子图对象
ax.bar(x=(0.2,0.6,0.8,1.2),height=(1,2,3,0.5),width=0.1)
#bar用于绘制直方图,x为柱子的横坐标,height为柱子高度,width表示柱子宽度
#一般来说x,height等参量可以为元组也可以为列表
#画横向直方图时,调用barh并且将参数中的x改为y
ax.set_title('我的直方图')#设置直方图的名称
plt.show()#显示直方图
(2)绘制堆叠直方图
import matplotlib.pyplot as plt#引入matplotlib包中的pyplot
ax=plt.figure().add_subplot()#建图,获取子图对象ax
labels=['Jan','Feb','Mar','Apr']#横坐标
num1=[20,30,15,35]#Dept1的数据
num2=[15,30,40,20]#Dept2的数据
cordx=range(len(num1))#x轴刻度位置
ax.bar(x=cordx,height=num1,width=0.5,color='red',label='Dept1')#绘制第一个直方图
#color可以设置直方图的颜色,label用于指明直方图的标签
ax.bar(x=cordx,height=num2,width=0.5,color='green',label='Dept2',bottom=num1)#绘制第二个直方图
#bottom用于指示每根柱子的底部有多高
ax.set_title('My Company')#设置直方图的名称
ax.set_ylim(0,100)#设置y轴坐标范围,如果不设置,python会自动调整到合适范围
ax.set_ylabel("Profit")#设置y轴标签
ax.set_xlabel("In year 2020")#设置x轴标签
ax.set_xticks(cordx)#设置x轴刻度位置
ax.set_xticklabels(labels)#设置x轴刻度下方文字
ax.legend()#在右上角显示图例说明
plt.show()
(3)绘制对比直方图
import matplotlib.pyplot as plt#引入matplotlib包中的pyplot
ax=plt.figure(figsize=(10,5)).add_subplot()#建图,获取子图对象ax,figsize用于指定窗口的大小
ax.set_ylim(0,400)#指定y轴范围
ax.set_xlim(0,80)#指定x轴范围
x1=[7,17,27,37,47,57]#第一组直方图每个柱子中心点的横坐标
x2=[13,23,33,43,53,63]#第二组直方图每个柱子中心点的横坐标
x3=[10,20,30,40,50,60]#第三组直方图每个柱子中心点的横坐标
#三组直方图高度
y1=[41,39,56,89,102,31]
y2=[56,257,344,12,98,123]
y3=[125,67,89,363,46,57]
rects1=ax.bar(x=x1,height=y1,width=3,color='red',label='Iphone')#绘制第一个直方图
rects2=ax.bar(x=x2,height=y2,width=3,color='green',label='Huawei')#绘制第二个直方图
rects3=ax.bar(x=x3,height=y3,width=3,color='blue',label='Xiaomi')#绘制第三个直方图
ax.set_xticks(x3)#设置x轴刻度位置
ax.set_xticklabels(('A1','A2','A3','A4','A5','A6'))#设置x轴刻度下方文字
ax.legend()#在右上角显示图例说明
def label(ax,rects):#在每个柱子顶端标记数值
for rect in rects:#rects代表一组直方图,是一个序列,则rect表示每个柱子
height=rect.get_height()#显示数值的高度位置
ax.text(rect.get_x()+rect.get_width()/2.0,height+14,str(height),rotation=90)
#text()可以在子图任意位置写文字,第一个参数为写文字的位置的横坐标,get_x()得到的是柱子左端坐标,第二个参数是书写高度
#第三个参数是所要书写的数值字符串,第四个参数rotation可以控制文字逆时针旋转的角度,可以不设定
label(ax,rects1)
label(ax,rects2)
label(ax,rects3)
plt.show()
(4)绘制折线图和散点图
import math,random
import matplotlib.pyplot as plt#引入matplotlib包中的pyplot
def drawPlot(ax):#在ax上画出散点图,折线图
#画曲线y=10*sin(x)的折线图,因为点间隔很小,等价于画曲线图
xs=[i/100 for i in range(1500)]#1500个点的横坐标,间隔0.01
ys=[10*math.sin(x) for x in xs]#对应曲线y=10*sin(x)上的点的纵坐标
ax.plot(xs,ys,"red",label="Beijing")#画曲线y=10*sin(x),plot用于绘制折线图
#画散点图
ys=list(range(-18,18))
random.shuffle(ys)#随机排列ys
ax.scatter(range(16),ys[:16],c="blue")#画散点图,共有16个散点,scatter用于绘制散点图,注意参数中颜色参数一定要写c
#以各个散点为结点画折线图
ax.plot(range(16),ys[:16],"blue",label="Shanghai")#画折线
ax.legend()#在右上角显示图例说明
ax.set_xticks(range(16))#设置x轴刻度位置
ax.set_xticklabels(range(16))#设置x轴刻度下方文字
ax=plt.figure(figsize=(10,4),dpi=100).add_subplot()#dpi设置了清晰度
drawPlot(ax)
plt.show()
(5)绘制饼图
import matplotlib.pyplot as plt#引入matplotlib包中的pyplot
def drawPie(ax):#在ax上绘制饼图
lbs=('A','B','C','D')#四个扇区的标签
sectors=[16,29.55,44.45,10]#四个扇区的份额(百分比)
expl=[0,0.1,0,0]#四个扇区的突出程度
ax.pie(x=sectors,labels=lbs,explode=expl,
autopct='%.2f',shadow=True,labeldistance=1.1,pctdistance=0.6,startangle=90)
#autopct控制输出格式,shadow控制输出时是否有阴影效果,labeldistance控制输出标签的位置是半径的多少倍
#pctdistance控制输出百分比的位置是半径的多少倍,startangle控制从多少度开始以逆时针方向绘制扇形图
ax.set_title("Pie Sample")#设置饼图名称
ax=plt.figure().add_subplot()#建图,获取子图对象ax
drawPie(ax)
plt.show()
(6)绘制热力图
热力图用于展示二维数据:
import numpy as np
import matplotlib.pyplot as plt#引入matplotlib包中的pyplot
data=np.random.randint(0,100,30).reshape((5,6))#创建一个随机的5行6列的矩阵
print(data)
xlabels=['Beijing','Shanghai','Chengdu','Guangzhou','Hangzhou','Wuhan']#x轴显示的标签
ylabels=['2016','2017','2018','2019','2020']#y轴显示的标签
ax=plt.figure(figsize=(10,8)).add_subplot()#建图,获取子图对象ax
ax.set_xticks(range(len(xlabels)))#设置x轴刻度位置
ax.set_xticklabels(xlabels)#设置x轴刻度下方文字
ax.set_yticks(range(len(ylabels)))#设置y轴刻度位置
ax.set_yticklabels(ylabels)#设置y轴刻度下方文字
heatMp=ax.imshow(data,cmap=plt.cm.hot,aspect='auto',vmin=0,vmax=100)#绘制热力图
#cmap用于设置绘制图的风格,plt.cm.hot为暖色调,plt.cm.cool为冷色调
#vmin和vmax指定了热力图中的最小值与最大值,显示的颜色随之变化
for i in range(len(xlabels)):#在热力图对应格子上写上数字
for j in range(len(ylabels)):
ax.text(i,j,data[j][i],ha="center",va="center",color="blue",size=26)
#ha为水平对齐方式,va为垂直对齐方式
plt.colorbar(heatMp)#绘制右边的颜色数值对照柱
plt.xticks(rotation=45,ha="right")#将x轴刻度文字进行旋转,且水平方向右对齐
plt.title("Sales Volume(ton)")#也可以用ax.set_title()
plt.show()
(7)绘制雷达图
import matplotlib.pyplot as plt#引入matplotlib包中的pyplot
from matplotlib import rcParams
rcParams['font.family']=rcParams['font.sans-serif']='SimHei'
#设置中文支持,中文字体为简体黑体,当不需要中文时则不需要这两行
def drawRadar(ax):#在ax上绘制雷达图
pi=3.1415926
labels=['力量','经验','防守','发球','技术','速度']#6个属性名称
attrNum=len(labels)#属性种类数
data=[10,10,10,10,10,10]
angles=[2*pi*i/attrNum for i in range(attrNum)]#angles是以弧度为单位的6个属性对应的6条半径线的角度
angles2=[x*180/pi for x in angles]#angles2是以角度为单位的6个属性对应的6条半径线的角度
ax.set_title('马龙',y=1.05)#y指明标题的垂直位置是直径的多少倍
ax.set_ylim(0,10)#限定半径线上的坐标范围
ax.set_thetagrids(angles2,labels,fontproperties="SimHei")#绘制6个属性对应的6条半径和整个雷达图圆圈
ax.fill(angles,data,facecolor="r",alpha=0.25)#填充雷达图数据,alpha为透明度
ax=plt.figure().add_subplot(projection="polar")#生成极坐标形式的子图
drawRadar(ax)
plt.show()
#还可以绘制多幅雷达图的堆叠,略
(8)一个窗口绘制多幅子图
import math,random
import matplotlib.pyplot as plt#引入matplotlib包中的pyplot
from matplotlib import rcParams
rcParams['font.family']=rcParams['font.sans-serif']='SimHei'
def drawPlot(ax):#在ax上画出散点图,折线图
#画曲线y=10*sin(x)的折线图,因为点间隔很小,等价于画曲线图
xs=[i/100 for i in range(1500)]#1500个点的横坐标,间隔0.01
ys=[10*math.sin(x) for x in xs]#对应曲线y=10*sin(x)上的点的纵坐标
ax.plot(xs,ys,"red",label="Beijing")#画曲线y=10*sin(x),plot用于绘制折线图
#画散点图
ys=list(range(-18,18))
random.shuffle(ys)#随机排列ys
ax.scatter(range(16),ys[:16],c="blue")#画散点图,共有16个散点,scatter用于绘制散点图,注意参数中颜色参数一定要写c
#以各个散点为结点画折线图
ax.plot(range(16),ys[:16],"blue",label="Shanghai")#画折线
ax.legend()#在右上角显示图例说明
ax.set_xticks(range(16))#设置x轴刻度位置
ax.set_xticklabels(range(16))#设置x轴刻度下方文字
def drawPie(ax):#在ax上绘制饼图
lbs=('A','B','C','D')#四个扇区的标签
sectors=[16,29.55,44.45,10]#四个扇区的份额(百分比)
expl=[0,0.1,0,0]#四个扇区的突出程度
ax.pie(x=sectors,labels=lbs,explode=expl,
autopct='%.2f',shadow=True,labeldistance=1.1,pctdistance=0.6,startangle=90)
#autopct控制输出格式,shadow控制输出时是否有阴影效果,labeldistance控制输出标签的位置是半径的多少倍
#pctdistance控制输出百分比的位置是半径的多少倍,startangle控制从多少度开始以逆时针方向绘制扇形图
ax.set_title("Pie Sample")#设置饼图名称
def drawRadar(ax):#在ax上绘制雷达图
pi=3.1415926
labels=['力量','经验','防守','发球','技术','速度']#6个属性名称
attrNum=len(labels)#属性种类数
data=[10,10,10,10,10,10]
angles=[2*pi*i/attrNum for i in range(attrNum)]#angles是以弧度为单位的6个属性对应的6条半径线的角度
angles2=[x*180/pi for x in angles]#angles2是以角度为单位的6个属性对应的6条半径线的角度
ax.set_title('马龙',y=1.05)#y指明标题的垂直位置是直径的多少倍
ax.set_ylim(0,10)#限定半径线上的坐标范围
ax.set_thetagrids(angles2,labels,fontproperties="SimHei")#绘制6个属性对应的6条半径和整个雷达图圆圈
ax.fill(angles,data,facecolor="r",alpha=0.25)#填充雷达图数据,alpha为透明度
fig=plt.figure(figsize=(8,8))
ax=fig.add_subplot(2,2,1)#窗口分割成2*2,取位于第1个方格的子图
drawPie(ax)
ax=fig.add_subplot(2,2,2,projection="polar")#取位于第二个方格的子图
drawRadar(ax)
ax=plt.subplot2grid((2,2),(1,0),colspan=2)
#subplot2grid第一个参数(2,2)说明将子图分成2*2,第二个参数(1,0)说明取坐标(1,0)的格子,colspan=2说明取列宽为2
drawPlot(ax)
plt.figtext(0.05,0.05,'subplot sample')#显示左下角的图像标题
#两个0.05说明显示位置为窗口宽与高的0.05倍
plt.show()
十二.网络爬虫设计
1.爬虫的用途和原理
1)爬虫的用途:
①在网络上搜集数据(搜索引擎)
②模拟浏览器快速操作(如抢票,选课)
③模拟浏览器操作,替代填表等重复操作
2)最基本的爬虫写法:数据获取型爬虫的本质就是自动获取网页并抽取其中的内容
①手工找出合适的url(网址)
②用浏览器手工查找url对应的网页,并查看网页源码,找出包含想要内容的字符串的模式
③在程序中获取url对应的网页
④在程序中用正则表达式或BeautifulSoup库抽取网页中想要的内容并保存
#示例:获取百度图片的搜索结果图片
#在百度浏览器搜索图片desk,获取其相应网址如下:
#https://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&dyTabStr=MCwzLDIsNCw2LDEsNSw3LDgsOQ%3D%3D&word=desk
#分析上述网址,可以发现word=desk一句控制搜索内容,不妨将desk改为猫,则可以搜索猫的图片结果,任取一张猫的照片地址
#https://img1.baidu.com/it/u=3789058185,1808652640&fm=253&fmt=auto&app=120&f=JPEG?w=750&h=500
#右键查看搜索猫的图片的网页源代码,Ctrl+F进行搜索,输入图片网址,可以发现图片网址前都有thumbURL
#因此我们需要用爬虫搜索thumbURL来获取图片的网址
import re
import requests#requests用于获取网络资源
def getHtml(url):#获取网址为url的网页
fakeHeaders = {'User-Agent': #用于伪装浏览器发送请求
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) \ '
'Chrome/81.0.4044.138 Safari/537.36 Edg/81.0.416.77',
'Accept': 'text/html,application/xhtml+xml,*/*'}
try:
r=requests.get(url,headers=fakeHeaders)
r.encoding=r.apparent_encoding#确保网页编码正确
return r.text#返回值是一个字符串,内含整个网页的内容
except Exception as e:
print(e)
return ""
def getBaiduPictures(word,n):#下载n个百度图片搜索的关于word的图片到本地
url="https://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&dyTabStr=MCwzLDIsNCw2LDEsNSw3LDgsOQ%3D%3D&word="
url+=word#补充完整的网址
html=getHtml(url)#获取网址对应的网页
pt='\"thumbURL\":.*?\"(.*?)\"'#用于寻找图片网址的正则表达式
i=0#用来记录取了多少幅图
for x in re.findall(pt,html):#x是图片url的网址,findall用于根据正则表达式pt,寻找html中相应的网址
x=x.replace("%3A",":")
x=x.replace("%2F","/")#有时网址中用%3A来表示:,用%2F来表示/
if not(x.lower().find("jpg")!=-1 or x.lower().find("jpeg")!=-1 or x.lower().find("png")!=-1):
continue#只取.png和.jpg图片
try:
print(x)
r=requests.get(x,stream=True)#获取x对应的网络资源,stream=True说明获取二进制形式的图片
pos1=x.rfind("&f=")#获取后缀名的下标
pos2=x.rfind("?")
f=open("F:/tmp/{0}{1}{2}".format(word,i,"."+x[pos1+3:pos2].lower()),"wb")#表示以二进制写方式打开文件
f.write(r.content)#将图片内容写入文件
f.close()
except Exception as e:
print(e)
i=i+1
if i>=n:
break
getBaiduPictures("熊猫",3)#存储3张熊猫图片到相应地址
上述代码原来if语句写的是:
if not(x.lower().endswith(".jpg") or x.lower().endswith(".jpeg") or x.lower().endswith(".png")):
continue#只取.png和.jpg图片
但是发现爬取失败,经过查看各个图片网址可以发现,各个图片网址格式为:u=623374478,4175757280&fm=253&fmt=auto&app=138&f=JPEG (500×658) (baidu.com)
因此并不能正确得爬取图片,因此对if语句进行了修改,查找字符串中得jpeg,jpg和png用于判断是否进行爬取
同时文件名的处理也做了相应的修改,最终爬取成功!!!
局限是requests库获取网络资源很容易被反爬虫,且不能获取JavaScript编写的动态网页源代码,可以尝试pyppeteer库,速度快且暂未被许多网站反爬
2.用pyppeteer库获取网页
pyppeteer的工作原理:
①启动一个浏览器Chromium,用浏览器装入网页
②从浏览器可以获取网页源代码,如果网页有JavaScript程序,获取到的是JavaScript被浏览器执行后的网页源代码
③可以向浏览器发出命令,模拟用户在浏览器上的键盘输入、鼠标点击等操作,让浏览器转到其他网页
十三.面向对象程序设计
1.类和对象的概念
类:类是用来代表事物的,对于一种事物,可以用一个类来概括其属性
对象:类的实例称为对象,类主要用于将数据和操作数据的函数捆绑在一起,便于当作一个整体使用
#矩形类示例:
class rectangle:
def __init__(self,w,h):#构造函数,每一个类必须有,self称为类的自身,注意构造函数init两侧是双下划线__而不是_!!!
self.w,self.h=w,h
def area(self):#类的每个成员函数都需要有self参数
return self.w*self.h
def perimeter(self):
return 2*(self.w+self.h)
def main():
w,h=map(int,input().split())#假设输入2 3
rect=rectangle(2,3)#生成一个rectangle对象
print(rect.area(),rect.perimeter())#6 10,#调用成员函数时不需要给self分配对应的实参
rect.w,rect.h=4,5
print(rect.area(),rect.perimeter())#20 18
main()
2.对象的比较
python中所有的类都有eq,ne等方法用于比较(注意双下划线)
#x==y的值就是x.__eq__(y)的值,如果x.__eq__(y)没有定义,那么就是y.__eq__(x)的值,如果x.__eq__(y)和y.__eq__(x)都没有定义,那么x==y也没有意义(x,y都是整数常量时不适用)
#x!=y的值就是x.__ne__(y)的值,如果x.__ne__(y)没有定义,那么就是y.__ne__(x)的值,如果x.__ne__(y)和y.__ne__(x)都没有定义,那么x!=y也没有意义,默认情况下x.__ne__(y)等价于not x.__eq__(y)
#x<y等价于x.__lt__(y)
#x>y等价于x.__gt__(y)
#x<=y等价于x.__le__(y)
#x>=y等价于x.__ge__(y)
print(24.5.__eq__(24.5))#True
print(10.0.__ne__(10.0))#False
print(25.7.__le__(45.5))#True
自定义对象的比较:
#默认情况下,一个自定义类的__eq__方法,功能是判断两个对象的id是否相同,即是否指向同一内存
#默认情况下,自定义类的lt,gt,le,ge都被设置成了None,因此不能比较大小,若想比较大小需重新编写这几个函数
class point:
def __init__(self,x,y=0):#y的缺省值设为0
self.x,self.y=x,y
def __eq__(self,other):
return self.x==other.x and self.y==other.y
def __lt__(self,other):#使得两个point对象可以用<进行比较
if self.x==other.y:
return self.y<other.y
else:
return self.x<other.x
a,b=point(1,2),point(1,2)
print(a==b)#True
print(a<b)#False
lst=[point(1,2),point(3,4),point(-7,2)]
lst.sort()
for p in lst:
print("(%d,%d)"%(p.x,p.y),end="")#(-7,2) (1,2) (3,4)
3.继承与派生
定义一个新类B时,如果发现B类具有A类的全部特点,则可以在定义B类时以A为基类,定义B类为A类的派生类
import datetime
class student:#定义一个学生类
def __init__(self,id,name,gender,birthYear):
self.id,self.name,self.gender,self.birthYear = id,name,gender,birthYear
def printInfo(self):#打印学生信息
print("Name:",self.name)
print("ID:", self.id)
print("Birth Year:",self.birthYear)
print("Gender:",self.gender)
print("Age:",self.countAge())
def countAge(self):#获取学生年龄
return datetime.datetime.now().year - self.birthYear
class undergraduateStudent(student): #本科生类,继承了student类
def __init__(self,id,name,gender,birthYear,department):#相比于student类,多了一个院系成员
student.__init__(self,id,name,gender,birthYear)#可以直接调用student类的构造函数,注意此时要带self
self.department = department
def qualifiedForBaoyan(self): #给予保研资格
print(self.name + " is qualified for baoyan")
def printInfo(self): #基类中有同名方法
student.printInfo(self) #调用基类的PrintInfo
print("Department:" ,self.department)
def main():
s2 = undergraduateStudent("118829212","Harry Potter","M",2000, "Computer Science")
s2.printInfo()
s2.qualifiedForBaoyan()
if s2.countAge() > 18:
print(s2.name , "is older than 18")
main()
object类:python中所有类都是object类的派生类,因而具有object类的各种属性和方法
class A:
def func(x):
pass
print(dir(A))#输出A的方法
#['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'func'],除了最后的func是自定义的,其他的都是object类的方法
4.静态属性和静态方法
静态属性:静态属性被所有对象所共享,一共只有一份
静态方法:静态方法不是作用在具体的某个对象上,因此不能访问非静态属性
静态属性和静态方法这种机制存在的目的就是少写全局变量和全局函数
class employee:
totalSalary = 0 #静态属性,记录发给员工的工资总数
def __init__(self,name,income):
self.name,self.income = name, income
def pay(self,salary):#发工资
self.income += salary
employee.totalSalary += salary#因为是静态成员变量,所以前面不写self,而是写类名employee
@staticmethod#说明下面定义的函数为静态方法
def printTotalSalary(): # 静态方法,只能访问静态成员变量,因此没有self
print(employee.totalSalary)
e1 = employee("Jack",0)
e2 = employee("Tom",0)
e1.pay(100)
e2.pay(200)
employee.printTotalSalary() #>>300,静态方法的调用可以通过类名
e1.printTotalSalary() #>>300,静态方法的调用也可以通过对象名,但是该方法于该具体对象之间没有关系
e2.printTotalSalary() #>>300
print(employee.totalSalary) #>>300
5.对象作为集合元素或字典的键
(1)可哈希:可哈希的东西才可以作为字典的键和集合的元素,hash(x)有定义即hash(x)有返回值,说明x是可哈希的
#hash(x)=x,如果x为整型常量
#hash(x)=x.__hash__(),如果x不是整型常量
#object类有hash方法,返回值是一个整数
#列表,字典,集合的__hash__成员函数都被定义为None,因此它们不能作为字典的键和集合的元素
x=23.1
print(x.__hash__(),23.1.__hash__())#230584300921372695 230584300921372695,只要变量值相同,算出来的哈希值就相同
x=23
print(x.__hash__(),hash(23))#23 23
x="OK"
print(hash(x))#-5537884497696122570
(2)哈希值和字典、集合的关系
字典和集合都是一种称为”哈希表“的数据结构,根据元素的哈希值为元素寻找存放的槽,哈希值可以看作是槽编号,一个槽中可以放多个哈希值相同的元素。
两个对象的哈希值不同可以作为同一集合的不同元素和同一字典的不同键,当hash(a)==hash(b)但是a!=b时,a,b也可以作为同一集合的不同元素和同一字典的不同键,自定义类的对象在默认情况下哈希值的计算是根据对象的id计算的(即存储地址),而非对象的值,可以重写自定义类的hash方法
若 dt 是个字典,dt[x] 计算过程如下:
-
根据hash(x)去找x应该在的槽的编号
-
如果该槽没有元素,则认为dt中没有键为x的元素
-
如果该槽中有元素,则试图在槽中找一个元素y,使得 y的键 == x。 如果找到,则dt[x] 即为 y的值,如果找不到,则dt[x]没定义,即 认为dt中不存在键为x的元素
class A:
def __init__(self,x):
self.x=x
a,b=A(5),A(5)#两个A(5)不是同一个,因此a和b的id不同
dt={a:20,A(5):30,b:40}#三个A(5)的id不同,因此在不同的槽里
print(dt[a],dt[b])#20 40
#print(dt[A(5)]),runtime error,因为此处的A(5)是一个新的A(5)
(3)自定义类的对象是否可哈希
自定义类的对象在默认情况下哈希值的计算是根据对象的id计算的(即存储地址)
如果为自定义的类重写了eq(self,other)成员函数,则其 hash成员函数会被自动设置为None。这种情况下,该类就变成不可哈希的
一个自定义类,只有在重写了eq方法却没有重写hash方法的情况下,才是不可哈希的。
class A:
def __init__(self,x):
self.x=x
def __hash__(self):
return hash(self.x)
c=A(1)
dt={A(1):2,A(1):3,c:4}#三个元素的哈希值相同,但是id不同,它们在同一个槽里
print(dt[c])#4
十四.tkinter图形界面程序设计
1.控件概述
控件(widgets): 按钮、列表框、单选框、多选框、编辑框....
布局 :如何将控件摆放在窗口上合适的位置
事件响应: 对鼠标点击、键盘敲击、控件被点击等操作进行响应
对话框 :弹出一个和用户交互的窗口接受一些输入
import tkinter as tk
win=tk.Tk()#生成一个窗口
tk.Label(win,...)#在窗口win上生成一个标签label,该label的母体是win
ckb=tk.Checkbutton(win,...)#在窗口win上生成一个checkbutton
frm = tk.Frame(win,...)#在窗口上生成一个Frame框架
bt = tk.Button(frm,...)#在frm上生成一个Button
tkinter的扩展控件:
from tkinter import ttk,tk中的控件ttk都有且更加美观,并且ttk中还有一些tk不具有的控件
2.布局基础
用grid进行布局,grid布局在窗口上布置网格,控件放在网格单元里面居中摆放
import tkinter as tk
win=tk.Tk()#生成一个窗口
win.title("Hello")#指定窗口标题
label1=tk.Label(win,text="用户名:")#创建标签控件,并与之母体win进行绑定
label2=tk.Label(win,text="密码:")
etUsername=tk.Entry(win)#创建属于win的单行编辑框控件,用于输入用户名
etPassword=tk.Entry(win)#创建属于win的单行编辑框控件,用于输入密码
btLogin=tk.Button(win,text="登录")#创建属于win的按钮button控件
label1.grid(row=0,column=0,padx=5,pady=5)#Label1放在第0行第0列,上下左右都留白5像素
label2.grid(row=1,column=0,padx=5,pady=5)#Label2放在第1行第0列,上下左右都留白5像素
etUsername.grid(row=0,column=1,padx=5,pady=5)#用户名输入框放在第0行第1列
etPassword.grid(row=1,column=1,padx=5,pady=5)#密码输入框放在第1行第1列
btLogin.grid(row=2,column=0,columnspan=2,padx=5,pady=5)
#登录按钮放在第2行第0列,跨2列,说明占用了第2行第0列和第2行第1列
win.geometry("500x200") #设置窗口大小
win.columnconfigure(0,weight = 1)
#指定第0列增量分配权重为1,默认的增量分配权重为0,当窗口变宽时,根据每一列的增量分配权重按比例分配多出来的宽度
win.columnconfigure(1,weight = 1)
win.rowconfigure(0,weight = 1) #指定第0行增量分配权重为1
win.rowconfigure(1,weight = 1)
win.rowconfigure(2,weight = 1)
#同时grid函数还有参数sticky指明控件在单元格中的贴边方式,由EWSN四个字符控制
label2.grid(row=1,column=0,padx=5,pady=5,sticky="NE")#密码标签靠右上角
etUsername.grid(row=0,column = 1,padx=5,pady=5,sticky="E") #用户名编辑框靠右
etPassword.grid(row=1,column = 1,padx=5,pady=5,sticky="EWSN")#密码编辑框占满单元格
btLogin.grid(row=2,column=0,columnspan=2,padx=5,pady=5,sticky="SW") #登录按钮靠左下
win.mainloop()#显示窗口
默认情况下的grid规则:
1)一个单元格只能放一个控件,控件在单元格中居中摆放。
2)不同控件高宽可以不同,因此网格不同行可以不一样高,不同列也 可以不一样宽。但同一行的单元格是一样高的,同一列的单元格也 是一样宽的。
3)一行的高度,以该行中包含最高控件的那个单元格为准。单元格的 高度,等于该单元格中摆放的控件的高度(控件如果有上下留白, 还要加上留白的高度)。列宽度也是类似的处理方式。
4)若不指定窗口的大小和显示位置,则窗口大小和网格的大小一样, 即恰好能包裹所有控件;显示位置则由Python自行决定。
3.使用Frame控件进行布局
1)控件多了,要算每个控件行、列、rowspan,columnspan很麻烦
2)Frame控件上面还可以摆放控件,可以当作底板使用
3)可以在Frame控件上面设置网格进行Grid布局,摆放多个控件
import tkinter as tk
#该系统的整体思路是用Frame填充网格,将控件放在Frame上,相当于对控件进行封装
win = tk.Tk()#创建窗口
win.title('人事系统')#设置窗口标题
frm01Red = tk.Frame(win,bg="red",highlightthickness=2)#背景红色,边框宽度2
frm01Red.grid(row=0,column=1,columnspan=2,sticky="WE")#摆放Frame控件到网格grid的合适位置
tk.Label(frm01Red, text="姓名:").grid(row=0,column=0,padx=6,pady=6)#创建姓名Label与frm01Red绑定
tk.Entry(frm01Red).grid(row=0,column=1,padx=6,pady=6)
tk.Label(frm01Red, text="手机号:").grid(row=0,column=2,padx=6,pady=6)
tk.Entry(frm01Red).grid(row=0,column=3,padx=6,pady=6)
tk.Button(frm01Red,text="更新").grid(row=0,column=4,padx=6,pady=6)
frm00Blue = tk.Frame(win, bg="blue",highlightthickness=2)
frm00Blue.grid(row=0,column=0,rowspan=2,sticky="NS")#放在网格的第0行第0列,且跨2行
tk.Label(frm00Blue,text="筛选条件:").grid( row = 0,
padx=6,pady=6,sticky="W")
tk.Checkbutton(frm00Blue,text="男性").grid( row = 1,padx=6,pady=6)#checkbutton为单选按钮,因为只有1列,可以不指定列
tk.Checkbutton(frm00Blue,text="女性").grid( row = 2,padx=6,pady=6)
tk.Checkbutton(frm00Blue,text="博士").grid( row = 3,padx=6,pady=6)
tk.Label(frm00Blue,text="符合条件的名单:").grid( row = 4,padx=6,sticky="W")
nameList = tk.Listbox(frm00Blue)#创建列表框控件
nameList.grid(row=5,padx=6,pady=6)
for x in ['张三','李四','王五','李丽','刘娟']:
nameList.insert(tk.END,x) #将x插入到列表框尾部
frm21Green = tk.Frame(win, bg='green',highlightthickness=2)
frm21Green.grid(row=2,column=0,columnspan=2,sticky="WE")
tk.Label(frm21Green, text="提示:目前一切正常").grid(row=0,padx=6,pady=6)
frm11Yellow = tk.Frame(win, bg='yellow',highlightthickness=2)
frm11Yellow.grid(row=1,column=1,sticky="NSWE") #要贴住单元格四条边
frm11Yellow.rowconfigure(1,weight=1) #使得frm11Yellow中第1行高度会自动伸缩
frm11Yellow.columnconfigure(0, weight=1)
tk.Label(frm11Yellow,text="简历:").grid(row=0,padx=6,pady=6,sticky="W")
tk.Text(frm11Yellow).grid(row=1,padx=15,pady=15,sticky="NSWE")
# sticky="NSWE"使得该多行编辑框会自动保持填满整个单元格
win.rowconfigure(1, weight=1)
win.columnconfigure(1, weight=1)
win.mainloop()
4.控件属性和事件响应
(1)控件属性
1)有的控件有函数可以用来设置和获取其属性,或以字典下标的形式获取和设置其属性
lbHint = tk.Label(win,text = "请登录")
lbHint["text"] = "登录成功!" #修改lbHint的文字
txt = tk.Text(win)
txt.get(0.0, tk.END) #从第0行第0列开始,取全部文字
2)有的控件必须和一个变量相关联,取变量值或设置变量值,就是取或设置该控件的属性
s = tk.StringVar()#s是tk中的字符串变量
s.set("sin(x)")#对字符串s进行赋值
tk.Entry(win,textvariable = s)#设定单行编辑框中的内容为s,编辑框中的文字和s关联到了一起,编辑框中内容改变,s也改变
print(s.get())
(2)事件响应
1)创建有些控件时,可以用command参数指定控件的事件响应函数
tk.Button(win,text="显示函数图",command = myfunc) #myfunc是函数名
tk.Checkbox(win,text="显示函数图",command = lambda:print("hello"))#checkbox是单选框
2)可以用控件的bind函数指定事件响应函数
lb = tk.Label(win,text="something")
lb.bind("<ButtonPress-1>",mouse_down) #鼠标左键按下事件,调用自定义的mouse_down函数
示例:
import tkinter as tk
def btLogin_click(): #登录按钮的事件响应函数,点击该按钮时被调用
if username.get()=="wzt" and password.get()=="123456789": #正确的用户名和密码,get()得到对应的字符串
lbHint["fg"] = "black" #文字变成黑色,"fg"表示前景色,"bg"表示背景色
lbHint["text"] = "登录成功!" #修改lbHint的文字
else:
username.set("") #将用户名输入框清空
password.set("") #将密码输入框清空
lbHint["fg"] = "red" #文字变成红色
lbHint["text"] = "用户名密码错误,请重新输入!"
def cbPassword_click(): #"显示密码"单选框的事件响应函数,点击该单选框时被调用
if showPassword.get():#showPassword是和cbPassword绑定的tkinter布尔变量
etPassword["show"] = "" #使得密码输入框能正常显示密码。Entry有show属性
else:
etPassword["show"] = "*"
win = tk.Tk()#创建窗口
win.title("登录")
username,password = tk.StringVar(),tk.StringVar()#两个字符串类型变量,分别用于关联用户名输入框和密码输入框
lbHint = tk.Label(win,text = "请登录")
lbHint.grid(row=0,column=0,columnspan=2)
lbUsername = tk.Label(win,text="用户名:")
lbUsername.grid(row=1,column=0,padx=5,pady=5)
lbPassword = tk.Label(win,text="密码:")
lbPassword.grid(row=2,column=0,padx=5,pady=5)
etUsername = tk.Entry(win,textvariable = username)#输入框etUsername和变量username关联
etUsername.grid(row=1,column = 1,padx=5,pady=5)
etPassword = tk.Entry(win,textvariable = password,show="*")
#Entry的属性show="*"表示该输入框不论内容是啥,只显示'*'字符,为""则正常显示
etPassword.grid(row=2,column = 1,padx=5,pady=5)
showPassword=tk.BooleanVar()#tk中的bool类型量,用于关联显示密码的单选框
showPassword.set(False)#使得cbPassword开始就是非选中状态
cbPassword = tk.Checkbutton(win,text="显示密码",variable=showPassword,command=cbPassword_click)
#cbPassword关联变量showPassword,其事件响应函数是cbPassword_click,即点击它时会调用 cbPassword_cli ck()
cbPassword.grid(row=3,column = 0,padx=5,pady=5)
btLogin = tk.Button(win,text="登录",command=btLogin_click)#点击btLogin按钮会执行btLogin_click()
btLogin.grid(row=4,column=0,pady=5)
btQuit = tk.Button(win,text="退出",command=win.quit)
#点击btQuit会执行win.quit(),win.quit()导致窗口关闭,于是整个程序结束
btQuit.grid(row=4,column=1,pady=5)
win.mainloop()
5.Python实例:火锅店点菜系统
import tkinter as tk
from tkinter import ttk #ttk中有更多控件
gWin = None #表示窗口
gDishes = ( ("清汤(20元)","滋补(40元)","鸳鸯(60元)"), #锅底
("香菜(10元)","麻酱(20元)","韭花(20元)"), #佐料
("羊肉(30元)","肥牛(40元)","白菜(10元)","茼蒿(20元)")) #菜品
def addToListbox(listbox,lst):#向列表框中添加lst中的元素
for x in lst:
listbox.insert(tk.END,x) #将x添加到列表框尾部
def doDiscount():
gWin.discount = [1,0.9,0.8][gWin.custom.get()]
gWin.lbHint["text"] = "饭菜总价:" + str(int(gWin.totalCost*gWin.discount)) + "元"
gWin.lbHint["fg"] = "black"
def categoryChanged(event): #gWin.cbxCategory选项变化时被调用
gWin.lsbDishes.delete(0,tk.END) #删除全部内容,delete(x,y)删除第x项到第y项
idx = gWin.cbxCategory.current() #gWin.cbxCategory当前选中的是第idx项
addToListbox(gWin.lsbDishes,gDishes[idx]) #装入相应菜单
gWin.lsbDishes.select_set(0, 0)
def btAdd_click():
#btAdd["state"] = tk.DISABLED表示按钮不可点击 tk.NORMAL表示按钮可点击
sel = gWin.lsbDishes.curselection() #sel形如 (1,2,3),获取当前选中的菜品
if sel == ():
gWin.lbHint["text"] = "您还没有选中要添加的菜"
gWin.lbHint["fg"] = "red"
else:
dish = gWin.lsbDishes.get(sel)
price,num = int(dish[3:5]),gWin.dishNum.get()
gWin.lsbTable.insert(tk.END, "["+gWin.category.get()+"]"+dish+" X"+num)
gWin.totalCost += price * int(num)
gWin.lbHint["text"] = "饭菜总价:" + str(int(gWin.totalCost*gWin.discount)) + "元"
gWin.lbHint["fg"] = "black"
def btDelete_click():
sel = gWin.lsbTable.curselection()
if sel == ():
gWin.lbHint["text"] = "您还没有选中要删除的菜"
gWin.lbHint["fg"] = "red"
else:
for i in sel:
dish = gWin.lsbTable.get(i)
price = int(dish[7:9])
price *= int(dish[dish.index("X")+1:])
gWin.totalCost -= price
gWin.lbHint["text"] = "饭菜总价:" + str(int(gWin.totalCost*gWin.discount)) + "元"
gWin.lbHint["fg"] = "black"
for i in sel[::-1]:
gWin.lsbTable.delete(i)
def main():
global gWin#声明以下的gWin为全局变量
gWin = tk.Tk()
gWin.title("Python火锅店")
gWin.geometry("520x300")
gWin.totalCost, gWin.discount = 0, 1 # 为gWin添加属性总价和折扣,类似于封装
gWin.resizable(False,False) #gWin不可改变大小,使得窗口不可进行拖拽改变大小
lb = tk.Label(gWin,text="欢迎光临Python火锅店",bg="red",fg="white",font=('黑体', 20,'bold'))#bold为粗体
lb.grid(row=0,column=0,columnspan=4,sticky="EW")
gWin.category = tk.StringVar() #对应组合框gWin.cbxCategory收起状态显示的文字
gWin.cbxCategory = ttk.Combobox(gWin,textvariable=gWin.category)#创建组合框控件
gWin.cbxCategory["values"] = ("锅底", "佐料", "菜品") #下拉时显示的表象
gWin.cbxCategory["state"] = "readonly" #将gWin.cbxCategory设置为不可输入,只能选择,state设置组合框属性
gWin.cbxCategory.current(0) #选中第0项,缺省的情况下选中的默认为第0项锅底
gWin.cbxCategory.grid(row=1,column=0,sticky="EW")
gWin.lsbDishes = tk.Listbox(gWin,selectmode=tk.SINGLE,exportselection=False)
#exportselection使得列表框失去输入焦点也能保持选中项目,即选中后点击别的地方该选中不会消失
#selectmode表示选择模式,设置选择模式为只能单选
gWin.lsbDishes.bind("<Double-Button-1>", lambda e:btAdd_click())
#使得双击菜品也可以进行添加,即使得双击行为对应操作添加
gWin.lsbDishes.bind("<<ListboxSelect>>",lambda e:gWin.dishNum.set("1"))
#使得选中新菜品即选择列表框中新选项时,数量自动返回1
addToListbox(gWin.lsbDishes,gDishes[0]) #装入锅底菜单
gWin.lsbDishes.select_set(0,0) #select_set(x,y)可以选中第x项到第y项(包括y),默认初始选中第0项菜品
gWin.lsbDishes.grid(row=2,column=0,sticky="EWNS")
gWin.cbxCategory.bind("<<ComboboxSelected>>",categoryChanged)
#当组合框下拉后有表现被选中时,会发生ComboboxSelected事件。
#此处指定该事件发生时,会调用gWin.categoryChanged函数
#指定"<<ComboboxSelected>>"事件的响应函数是gWin.categoryChanged
gWin.lsbTable = tk.Listbox(gWin,selectmode=tk.EXTENDED,exportselection=False)
#selectmode=tk.EXTENDED说明可以多选
gWin.lsbTable.grid(row=2,column=2,sticky="EWNS")
tk.Label(gWin,text="我的餐桌").grid(row=1,column=2)
gWin.lbHint = tk.Label(gWin,text="饭菜总价:0元")#输出当前选中菜品总价的Label
gWin.lbHint.grid(row = 3,column=0,columnspan=3,sticky="W")
scrollbar = tk.Scrollbar(gWin,width=20, orient="vertical",command=gWin.lsbTable.yview)
#创建滚动条控件,宽度width为20个像素,方向orient为垂直方向
#command=gWin.lsbTable.yview使得滚动条和列表框相关联
gWin.lsbTable.configure(yscrollcommand=scrollbar.set) #绑定listbox和scrollbar,使得列表框和滚动条关联
scrollbar.grid(row=2,column=3,sticky="NS")
frm = tk.Frame(gWin)
frm.grid(row=2,column=1)
tk.Label(frm,text="数量:").grid(row=0,column=0)
gWin.dishNum = tk.StringVar(value="1")#tk字符串形式的变量,用于表示菜品数,初始值设为1
gWin.spNum = tk.Spinbox(frm,width=5,from_=1,to=1000,textvariable=gWin.dishNum)
#创建可调数量框控件,from_和to控制调节范围
gWin.spNum.grid(row=0,column=1)
btAdd = tk.Button(frm,text="添加",command=btAdd_click)
btAdd.grid(row=1,column=0,columnspan=2,sticky="EW")
btDelete = tk.Button(frm,text="删除",command=btDelete_click)
btDelete.grid(row=2,column=0,columnspan=2,sticky="EW")
lbfDiscount = tk.LabelFrame(frm,text="价格")#带标签的Frame
lbfDiscount.grid(row=3,column=0,columnspan=2)
gWin.custom = tk.IntVar() #如果写 gWin.custom = tk.IntVar(value=0)就不用下一行了
gWin.custom.set(0)#gWin.custom为tk的整型变量
rb = tk.Radiobutton(lbfDiscount,text="普通价",value=0,variable=gWin.custom,command=doDiscount)
rb.grid(row=0,column=0,sticky="W")#Radiobutton为单选框,如果它被选中,那么variable会变为0
rb = tk.Radiobutton(lbfDiscount,text="会员价(九折)",value=1,variable=gWin.custom,command=doDiscount)
rb.grid(row=1,column=0,sticky="W")
rb = tk.Radiobutton(lbfDiscount,text="VIP价(八折)",value=2,variable=gWin.custom,command=doDiscount)
rb.grid(row=2,column=0,sticky="W")
gWin.columnconfigure(0,weight = 1)
gWin.columnconfigure(2,weight = 1)
gWin.rowconfigure(2,weight = 1)
gWin.mainloop()
main()
十五.Python游戏设计
外星人入侵主要依靠pygame库进行设计,在此仅附上代码
1.aline_invasion.py
import sys
from time import sleep
import pygame#pygame包含开发游戏所需功能
from settings import Settings
from game_stats import GameStats
from ship import Ship
from bullet import Bullet
from aline import Aline
from button import Button
from scoreboard import ScoreBoard
class AlineInvasion:#管理游戏资源和行为的类
def __init__(self):#初始化游戏并创建游戏资源
pygame.init()#初始化游戏背景设置
self.settings=Settings()
self.screen=pygame.display.set_mode((0,0),pygame.FULLSCREEN)#全屏运行游戏
self.settings.screen_width=self.screen.get_rect().width
self.settings.screen_height=self.screen.get_rect().height#更新settings中的数据
pygame.display.set_caption("Aline Invasion")#设置窗口title
self.stats=GameStats(self)
self.sb=ScoreBoard(self)
self.ship=Ship(self)#self就是当前的AlineInvasion实例
self.bullets=pygame.sprite.Group()#编组,用于管理所有有效子弹
self.alines=pygame.sprite.Group()#
self._create_fleet()
self.play_button=Button(self,"Play")
def run_game(self):#开始游戏的主循环
while True:#监视键盘和鼠标事件
self._check_events()
if self.stats.game_active:
self.ship.update()
self._update_bullets()
self._update_alines()
self._update_screen()
def _check_events(self):
for event in pygame.event.get():#事件循环
if event.type==pygame.QUIT:#退出事件
sys.exit()#响应退出事件
elif event.type==pygame.KEYDOWN:#按键盘事件
self._check_keydown_events(event)
elif event.type==pygame.KEYUP:#松键盘事件
self._check_keyup_events(event)
elif event.type==pygame.MOUSEBUTTONDOWN:
mouse_pos=pygame.mouse.get_pos()#返回一个坐标
self._check_play_button(mouse_pos)
def _fire_bullet(self):
#创建一颗子弹,并将其加入编组中
if len(self.bullets)<self.settings.bullets_allowed:
new_bullet=Bullet(self)
self.bullets.add(new_bullet)
def _update_bullets(self):
self.bullets.update()#对编组调用update即为对其中每个元素都调用update
for bullet in self.bullets.copy():#遍历副本目的是为了保证循环过程中编组长度保持不变
if bullet.rect.bottom<=0:
self.bullets.remove(bullet)
self._check_bullet_aline_collisions()
def _check_bullet_aline_collisions(self):
#检测碰撞,即图片是否有重叠,比较两个Group,返回一个字典,字典元素的键是子弹,值是被击中的外星人
#两个布尔参数分别代表是否删除子弹和外星人
collisions=pygame.sprite.groupcollide(self.bullets,self.alines,True,True)
if collisions:
for alines in collisions.values():
self.stats.score+=self.settings.aline_points*len(alines)
self.sb.prep_score()
self.sb.check_high_score()
if not self.alines:
#删除现有的子弹并创建一批新的外星人
self.bullets.empty()
self._create_fleet()
self.settings.increase_speed()
self.stats.level+=1
self.sb.prep_level()
def _update_screen(self):
self.screen.fill(self.settings.bg_color)#每次循环时都重绘屏幕,fill设置背景颜色
self.ship.blitme()
for bullet in self.bullets.sprites():
bullet.draw_bullet()
self.alines.draw(self.screen)#绘制外星人群中的外星人
self.sb.show_score()
if not self.stats.game_active:
self.play_button.draw_button()
pygame.display.flip()#让最近绘制的屏幕可见
def _check_keydown_events(self,event):
if event.key==pygame.K_RIGHT:#右移事件
self.ship.moving_right=True
elif event.key==pygame.K_LEFT:#左移事件
self.ship.moving_left=True
elif event.key==pygame.K_q:#按Q退出游戏
sys.exit()
elif event.key==pygame.K_SPACE:
self._fire_bullet()
def _check_keyup_events(self,event):
if event.key==pygame.K_RIGHT:#右移事件
self.ship.moving_right=False
elif event.key==pygame.K_LEFT:#左移事件
self.ship.moving_left=False
def _create_fleet(self):#创建外星人群
aline=Aline(self)#创建一个外星人
#外星人的间距为外星人的宽度
aline_width,aline_height=aline.rect.size
available_space_x=self.settings.screen_width-(2*aline_width)
number_alines_x=available_space_x//(2*aline_width)
ship_height=self.ship.rect.height
available_space_y=self.settings.screen_height-3*aline_height-ship_height
number_rows=available_space_y//(2*aline_height)
#创建第一行外星人
for row_number in range(number_rows):
for aline_number in range(number_alines_x):
self._create_aline(aline_number,row_number)
def _create_aline(self,aline_number,row_number):
aline=Aline(self)
aline_width,aline_height=aline.rect.size
aline.x=aline_width+2*aline_number*aline_width
aline.rect.x=aline.x
aline.rect.y=aline.rect.height+2*aline.rect.height*row_number
self.alines.add(aline)
def _update_alines(self):
self._check_fleet_edges()
self.alines.update()
if pygame.sprite.spritecollideany(self.ship,self.alines):
#spritecollideany接受两个实参,一个精灵,一个编组,检测编组中成员是否与精灵发生碰撞
self._ship_hit()
self._check_alines_bottom()
def _check_fleet_edges(self):#有外星人到达边缘时采取相应措施
for aline in self.alines.sprites():
if aline.check_edges():
self._change_fleet_direction()
break
def _change_fleet_direction(self):
#将整群外星人下移并改变他们的方向
for aline in self.alines.sprites():
aline.rect.y+=self.settings.fleet_drop_speed
self.settings.fleet_direction*=-1
def _ship_hit(self):#响应飞船被外星人撞到
if self.stats.ships_left>0:
self.stats.ships_left-=1
self.sb.prep_ships()
#清空余下的外星人和子弹
self.alines.empty()
self.bullets.empty()
#创建一批新的外星人并将飞船放到屏幕底端的中央
self._create_fleet()
self.ship.center_ship()
sleep(0.5)#暂停0.5秒
else:
self.stats.game_active=False
pygame.mouse.set_visible(True)#显示鼠标光标
def _check_alines_bottom(self):#检测是否有外星人到达屏幕底端
screen_rect=self.screen.get_rect()
for aline in self.alines.sprites():
if aline.rect.bottom>=screen_rect.bottom:
self._ship_hit()
break
def _check_play_button(self,mouse_pos):
button_clicked=self.play_button.rect.collidepoint(mouse_pos)
if button_clicked and not self.stats.game_active:#判断点击的坐标是否在按钮的矩形内
self.settings.initialize_dynamic_settings()
self.stats.reset_stats()
self.stats.game_active=True
self.sb.prep_score()
self.sb.prep_level()
self.sb.prep_ships()
self.alines.empty()
self.bullets.empty()
self._create_fleet()
self.ship.center_ship()
pygame.mouse.set_visible(False)#隐藏鼠标光标
if __name__=="__main__":#创建游戏实例并运行游戏
ai=AlineInvasion()
ai.run_game()
2.game_stats.py
class GameStats:#跟踪游戏的统计信息
def __init__(self,ai_game):
self.settings=ai_game.settings
self.reset_stats()
self.game_active=False
self.high_score=0
def reset_stats(self):
#初始化在游戏期间可能发生变化的统计信息
self.ships_left=self.settings.ship_limit
self.score=0
self.level=1
3.scoreboard.py
import pygame.font
from pygame.sprite import Group
from ship import Ship
class ScoreBoard:#显示得分信息的类
def __init__(self,ai_game):
self.ai_game=ai_game
self.screen=ai_game.screen
self.screen_rect=self.screen.get_rect()
self.settings=ai_game.settings
self.stats=ai_game.stats
#显示得分信息时所用的字体设置
self.text_color=(30,30,30)
self.font=pygame.font.SysFont(None,48)
self.prep_score()
self.prep_high_score()
self.prep_level()
self.prep_ships()
def prep_score(self):
rounded_score=round(self.stats.score,-1)#让小数舍入到最近的10整数倍
score_str="{:,}".format(rounded_score)
self.score_image=self.font.render(score_str,True,self.text_color,self.settings.bg_color)
self.score_rect=self.score_image.get_rect()
self.score_rect.right=self.screen_rect.right-20
self.score_rect.top=20
def prep_high_score(self):
high_score=round(self.stats.high_score,-1)
high_score_str="{:,}".format(high_score)
self.high_score_image=self.font.render(high_score_str,True,self.text_color,self.settings.bg_color)
#将最高得分放在屏幕中央
self.high_score_rect=self.high_score_image.get_rect()
self.high_score_rect.centerx=self.screen_rect.centerx
self.high_score_rect.top=self.score_rect.top
def show_score(self):
self.screen.blit(self.score_image,self.score_rect)
self.screen.blit(self.high_score_image,self.high_score_rect)
self.screen.blit(self.level_image,self.level_rect)
self.ships.draw(self.screen)
def check_high_score(self):
if self.stats.score>self.stats.high_score:
self.stats.high_score=self.stats.score
self.prep_high_score()
def prep_level(self):
level_str=str(self.stats.level)
self.level_image=self.font.render(level_str,True,self.text_color,self.settings.bg_color)
self.level_rect=self.level_image.get_rect()
self.level_rect.right=self.score_rect.right
self.level_rect.top=self.score_rect.bottom+10
def prep_ships(self):
self.ships=Group()
for ship_number in range(self.stats.ships_left):
ship=Ship(self.ai_game)
ship.rect.x=10+ship_number*ship.rect.width
ship.rect.y=10
self.ships.add(ship)
4.button.py
import pygame.font
class Button:
def __init__(self,ai_game,msg):
#初始化按钮属性
self.screen=ai_game.screen
self.screen_rect=self.screen.get_rect()
#设置按钮大小和其他属性
self.width,self.height=200,50
self.button_color=(0,255,0)#按钮颜色
self.text_color=(255,255,255)#文本颜色
self.font=pygame.font.SysFont(None,48)#None指字体为默认字体,48为字号
self.rect=pygame.Rect(0,0,self.width,self.height)
self.rect.center=self.screen_rect.center
self._prep_msg(msg)
def _prep_msg(self,msg):
self.msg_image=self.font.render(msg,True,self.text_color,self.button_color)
#font.render用于将文本转为图像
#布尔实参表示是否开启反锯齿功能,使得字体变得更加平滑
self.msg_image_rect=self.msg_image.get_rect()
self.msg_image_rect.center=self.rect.center
def draw_button(self):
self.screen.fill(self.button_color,self.rect)#绘制表示按钮的矩形
self.screen.blit(self.msg_image,self.msg_image_rect)#绘制文本图像
5.aline.py
import pygame
from pygame.sprite import Sprite
class Aline(Sprite):
#表示单个外星人的类
def __init__(self,ai_game):
super().__init__()
self.screen=ai_game.screen
self.settings=ai_game.settings
self.image=pygame.image.load("images/aline.bmp")
self.rect=self.image.get_rect()#获取其外接矩形,用其来处理位置
#每个外星人最初都在屏幕左上角附近
self.rect.x=self.rect.width
self.rect.y=self.rect.height
self.x=float(self.rect.x)
def update(self):
#向右移动外星人
self.x+=(self.settings.aline_speed*self.settings.fleet_direction)
self.rect.x=self.x
def check_edges(self):#检查外星人是否撞到了边缘
screen_rect=self.screen.get_rect()
if self.rect.right>=screen_rect.right or self.rect.left<=0:
return True
6.ship.py
import pygame
from pygame.sprite import Sprite
class Ship(Sprite):#管理飞船的类
def __init__(self,ai_game):#ai_game为指向当前AlineInvasion实例的引用
#初始化飞船并设置其初始位置
super().__init__()
self.screen=ai_game.screen
self.settings=ai_game.settings
self.screen_rect=ai_game.screen.get_rect()#将屏幕当作矩形处理
#加载飞船图像并获取其外接矩形
self.image=pygame.image.load('images/ship.bmp')
self.rect=self.image.get_rect()#获取其外接矩形,用其来处理位置
#对于每艘新飞船,将其放在屏幕底部的中央
self.rect.midbottom=self.screen_rect.midbottom
#在飞船的属性x中存储小数值
self.x=float(self.rect.x)
self.moving_right=False
self.moving_left=False
def blitme(self):#在指定位置绘制飞船
self.screen.blit(self.image,self.rect)
def update(self):
if self.moving_right and self.rect.right<self.screen_rect.right:
self.x+=self.settings.ship_speed
if self.moving_left and self.rect.left>0:
self.x-=self.settings.ship_speed
#根据self.x更新self.rect.x
self.rect.x=self.x
def center_ship(self):
self.rect.midbottom=self.screen_rect.midbottom
self.x=float(self.rect.x)
7.settings.py
class Settings:#存储游戏外星人入侵中所有的类
def __init__(self):#初始化游戏的设置
#屏幕设置
self.screen_width=1200
self.screen_height=800
self.bg_color=(230,230,230)
#飞船设置
self.ship_limit=3#飞船个数
#子弹设置
self.bullet_width=3
self.bullet_height=15
self.bullet_color=(60,60,60)#深灰色
self.bullets_allowed=3#最大子弹数
#外星人设置
self.fleet_drop_speed=10#下降速度
#加快游戏节奏的速度
self.speedup_scale=1.1
self.score_scale=1.5
self.initialize_dynamic_settings()
def initialize_dynamic_settings(self):
self.ship_speed=1.5
self.bullet_speed=1.5
self.aline_speed=1.0
self.fleet_direction=1#1表示右移,-1表示左移
self.aline_points=50
def increase_speed(self):
self.ship_speed*=self.speedup_scale
self.bullet_speed*=self.speedup_scale
self.aline_speed*=self.speedup_scale
self.aline_points=int(self.aline_points*self.score_scale)
8.bullet.py
import pygame
from pygame.sprite import Sprite
class Bullet(Sprite):#由类Sprite派生
#管理飞船所发射子弹的类
def __init__(self,ai_game):#在飞船当前位置创建一个子弹对象
super().__init__()
self.screen=ai_game.screen
self.settings=ai_game.settings
self.color=self.settings.bullet_color
#在(0,0)处创建一个表示子弹的矩形,再设置正确位置
self.rect=pygame.Rect(0,0,self.settings.bullet_width,self.settings.bullet_height)
self.rect.midtop=ai_game.ship.rect.midtop
self.y=float(self.rect.y)
def update(self):
#向上移动子弹
self.y-=self.settings.bullet_speed
self.rect.y=self.y
def draw_bullet(self):
#在屏幕上绘制子弹
pygame.draw.rect(self.screen,self.color,self.rect)
十六.用opencv进行人脸识别
1.读取图片、灰度转换、修改尺寸
import cv2 as cv#导入opencv模块
img=cv.imread('images/face1.jpg')#导入图片
gray_img=cv.cvtColor(img,cv.COLOR_BGR2GRAY)#对图片进行灰度转换,cvtColor第一个参数是图片,第二个参数是转换的类型
resize_img=cv.resize(img,dsize=(200,200))#修改图片大小为200*200
cv.imshow('read_picture',img)#显示图片,第一个参数为窗口名,第二个参数为要显示的图片
cv.imshow('gray',gray_img)#显示灰度图片
cv.imshow('resize',resize_img)#显示改变大小后的图片
print("img:",img.shape)#img: (646, 665, 3),3代表通道数RGB
print("resize_img:",resize_img.shape)#resize_img: (200, 200, 3)
cv.imwrite('images/face1_gray.jpg',gray_img)#保存图片
while True:
if ord('q')==cv.waitKey(0):#输入q停止显示,waitkey没按键时返回-1
break;
#cv.waitKey(0)设置图片显示时间,填0表示图片在人为关闭之前可以一直显示
cv.destroyAllWindows()#程序结束,释放全部内存
2.绘制图形
import cv2 as cv#导入opencv模块
img=cv.imread('images/face1.jpg')#导入图片
x,y,w,h=100,100,100,100#矩形的坐标,x,y为起始坐标,w,h为宽和高
cv.rectangle(img,(x,y,x+w,x+h),color=(0,0,255),thickness=1)#绘制矩形
#rectangle第一个参数为图片,第二个参数为四元组代表绘制矩形的左上角和右下角的坐标,color为矩形颜色,thickness为线条宽度
cv.circle(img,center=(x+w//2,y+h//2),radius=100,color=(255,0,0),thickness=2)#绘制圆形
#center为圆心坐标,radius为半径
cv.imshow('img',img)
while True:
if ord('q')==cv.waitKey(0):#输入q停止显示
break
#cv.waitKey(0)设置图片显示时间,填0表示图片在人为关闭之前可以一直显示
cv.destroyAllWindows()#程序结束,释放全部内存
3.人脸检测
import cv2 as cv#导入opencv模块
def face_detect_demo(img):
gray_img=cv.cvtColor(img,cv.COLOR_BGR2GRAY)#转换成灰度图片
face_detect=cv.CascadeClassifier(r"D:\opencv\opencv\sources\data\haarcascades\haarcascade_frontalface_alt2.xml")
#配置分类器,opencv提供了识别多种特征的分类器,在此直接使用即可
face=face_detect.detectMultiScale(gray_img)#得到绘制矩形的位置和宽和高,如果检测到多张人脸则会返回多组数据
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
#注意此处第二个参数不是四元组而是两个坐标,代表矩形的左上角和右下角的坐标
cv.imshow('result',img)
img=cv.imread('images/face2.jpg')#导入图片
face_detect_demo(img)
while True:
if ord('q')==cv.waitKey(0):#输入q停止显示
break
#cv.waitKey(0)设置图片显示时间,填0表示图片在人为关闭之前可以一直显示
cv.destroyAllWindows()#程序结束,释放全部内存
详解detectMultiScale:
此方法的任务是检测不同大小的对象,并返回矩形的列表。
第1个参数img需要是灰度图片
第2个参数scaleFactor,很重要
第3个参数minNeighbors,很重要
第4个参数flag=0即可
第5,6个参数minSize和maxSize 设置检测对象的最大最小值,低于minSize和高于maxSize的话就不会检测出来。参数类型为二元组,指定矩形的最小范围和最大范围
scaleFactor默认为1.1,Haar cascade的工作原理是一种“滑动窗口”的方法,通过在图像中不断的“滑动检测窗口”来匹配人脸。
因为图像的像素有大有小,图像中的人脸因为远近不同也会有大有小,所以需要通过scaleFactor参数设置一个缩小的比例,对图像进行逐步缩小来检测,这个参数设置的越大,计算速度越快,但可能会错过了某个大小的人脸。可以根据图像的像素值来设置此参数,像素大缩小的速度就可以快一点,通常在1~1.5之间。
minNeighbors默认为3,指定每个候选矩形有多少个“邻居”,指定每个候选矩形有多少个“邻居”,也可以理解为检测次数,只有检测minNeighbors次,某处都识别为人脸才会显示出来矩形
4.视频人脸检测
import cv2 as cv#导入opencv模块
def face_detect_demo(img):
gray_img=cv.cvtColor(img,cv.COLOR_BGR2GRAY)#转换成灰度图片
face_detect=cv.CascadeClassifier(r"D:\opencv\opencv\sources\data\haarcascades\haarcascade_frontalface_alt2.xml")
#配置分类器,opencv提供了识别多种特征的分类器,在此直接使用即可
face=face_detect.detectMultiScale(gray_img)#得到绘制矩形的位置和宽和高,如果检测到多张人脸则会返回多组数据
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
#注意此处第二个参数不是四元组而是两个坐标,代表矩形的左上角和右下角的坐标
cv.imshow('result',img)
cap=cv.VideoCapture(0)#VideoCapture用于获取摄像头,参数为0代表获取电脑默认摄像头
#cap=cv.VideoCapture("videos/video1.mp4")#VideoCapture也可以用于获取视频
while True:
flag,frame=cap.read()#read()用于获取当前视频是否在播放以及当前帧,返回一个二元组
if not flag:#视频播放结束
break
face_detect_demo(frame)
if ord('q')==cv.waitKey(1):
#注意如果想要视频持续播放的话,可以在检测时持续按住空格,或者将waitkey中的参数调为非0
break
#cv.waitKey(0)设置图片显示时间,填0表示图片在人为关闭之前可以一直显示
cv.destroyAllWindows()#程序结束,释放全部内存
cap.release()#释放摄像头
5.人脸录入
import cv2 as cv
cap=cv.VideoCapture(0)
flag=0
num=1
while(cap.isOpened()):#检测摄像头是否在开启状态
ret_flag,Vshow=cap.read()#得到每帧图像
cv.imshow("Capture",Vshow)#显示图像
k=cv.waitKey(1) & 0xFF#按键判断
if k==ord('s'):#按下s保存截图
cv.imwrite("images/data/"+str(num)+".name.jpg",Vshow)
num+=1
if k==ord(' '):#按空格结束
break
cap.release()
cv.destroyAllWindows()
6.数据训练
#pip install 包名 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
import cv2 as cv
import os
from PIL import Image
import numpy as np
def getImageAndLabels(path):
facesSamples=[]#存储人脸数据
ids=[]#存储姓名数据
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]#存储各个图片路径信息
#os.path.join()用于将路径与文件名合成一个字符串,os.listdir()用于获取当前文件夹下的文件名
face_detector=cv.CascadeClassifier(r"D:\opencv\opencv\sources\data\haarcascades\haarcascade_frontalface_alt2.xml")
#加载分类器
for imagePath in imagePaths:#遍历图片
PIL_img=Image.open(imagePath).convert('L')#以灰度图像的方式打开图片
img_numpy=np.array(PIL_img,'uint8')#将获取的灰度图像转化为数组,uint8代表8位无符号整数
faces=face_detector.detectMultiScale(img_numpy)
#img_numpy是一整张图片的数据数组,经过分类器之后是faces,是人脸那一个部分的数据数组
id=int(os.path.split(imagePath)[1].split('.')[0])#获取图像id
#将路径中的文件名提取出来,再以.作为分割提取出第一个数字作为id
for x,y,w,h in faces:
ids.append(id)
facesSamples.append(img_numpy[y:y+h,x:x+w])
return facesSamples,ids
if __name__=='__main__':
path="images/data/"#存放图片的路径
faces,ids=getImageAndLabels(path)#获取图像数组和id标签数组
recognizer=cv.face.LBPHFaceRecognizer_create()#加载识别器
recognizer.train(faces,np.array(ids))#进行数据训练
recognizer.write("trainer/trainer1.yml")#将数据保存
7.人脸识别
import cv2 as cv
import os
import urllib
import urllib.request
def face_detect_demo(img):
gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY)#图像灰度化
face_detect=cv.CascadeClassifier(r"D:\opencv\opencv\sources\data\haarcascades\haarcascade_frontalface_alt2.xml")
#配置分类器,opencv提供了识别多种特征的分类器,在此直接使用即可
face=face_detect.detectMultiScale(gray)#得到绘制矩形的位置和宽和高,如果检测到多张人脸则会返回多组数据
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
#注意此处第二个参数不是四元组而是两个坐标,代表矩形的左上角和右下角的坐标
ids,confidence=recognizer.predict(gray[y:y+h,x:x+w])#confidence则是进行人脸检测后的评分,越大越不可信
if confidence>80:#不太可信,不是训练集中的人
cv.putText(img,"Unknown",(x+10,y-10),cv.FONT_HERSHEY_SIMPLEX,0.75,(255,255,255),thickness=2)
else:
cv.putText(img,str(names[ids-1]),(x+10,y-10),cv.FONT_HERSHEY_SIMPLEX,0.75,(255,255,255),thickness=2)
#cv2.putText(图片img,“文本内容”,(左下角坐标),字体,字体大小,(颜色),线条粗细,线条类型)
cv.imshow("result",img)
recognizer=cv.face.LBPHFaceRecognizer_create()#加载识别器
recognizer.read("trainer/trainer1.yml")#加载训练数据集文件
names=[]#存储姓名
names.append("weiziteng")
cap=cv.VideoCapture(0)#VideoCapture用于获取摄像头,参数为0代表获取电脑默认摄像头
#cap=cv.VideoCapture("videos/video1.mp4")#VideoCapture也可以用于获取视频
while True:
flag,frame=cap.read()#read()用于获取当前视频是否在播放以及当前帧,返回一个二元组
if not flag:#视频播放结束
break
face_detect_demo(frame)
if ord('q')==cv.waitKey(1):
#注意如果想要视频持续播放的话,可以在检测时持续按住空格,或者将waitkey中的参数调为非0
break
#cv.waitKey(0)设置图片显示时间,填0表示图片在人为关闭之前可以一直显示
cv.destroyAllWindows()#程序结束,释放全部内存
cap.release()#释放摄像头
十七.scikit-learn实现机器学习
1.机器学习介绍及其原理
①人工智能:就其本质而言,是及其对人思维信息过程的模拟,让它能像人一样去思考
人工智能可以根据输入信息进行模型结构,权重更新,实现最终优化
特点:信息处理,自我学习,优化升级
②人工智能的核心方法:机器学习,深度学习
机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术
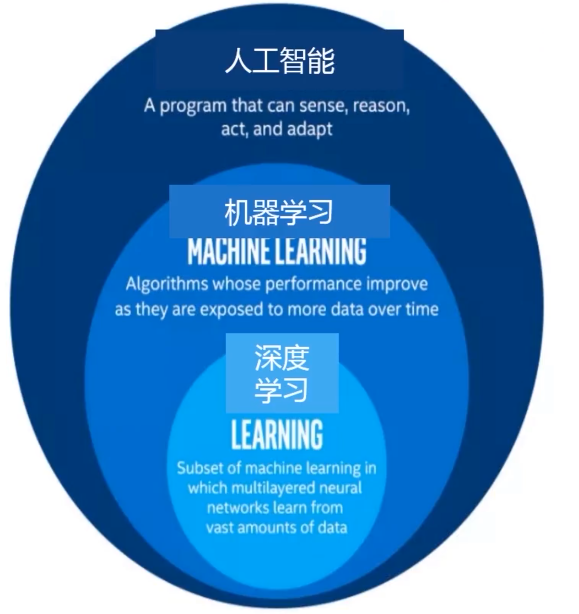
机器学习:使用算法来解析数据,从中学习,然后对真实世界中的事件进行决策和预测
深度学习:模仿人类的神经网络,建立模型,进行数据分析
③机器学习分类:
监督式学习:基于数据及结果进行预测
非监督式学习:从数据中挖掘关联性
强化学习:强调如何基于环境而行动以获取最大利益
④监督式学习核心步骤:
1.使用标签数据训练机器学习模型
●"标签数据" 是指由输入数据对应的正确的输出结果
●"机器学习模型"将学习输入数据与之对应的输出结果间的函数关系
2.调用训练好的机器学习模型,根据新的输入数据预测对应的结果
相比于监督式学习,非监督式学习不需要标签数据,而是通过引入预先设定的优化准则进行模型训练,比如自动将数据分为三类
2.机器学习开发环境部署
1)Scikit-learn:是python语言中专门针对机器学习应用而发展起来的开源框架,可以实现数据预处理,分类,回归,降维,模型选择等常用的机器学习算法

2)Jupyter notebook

3)Anaconda


3.机器学习实现之数据预处理
1)Iris数据集:

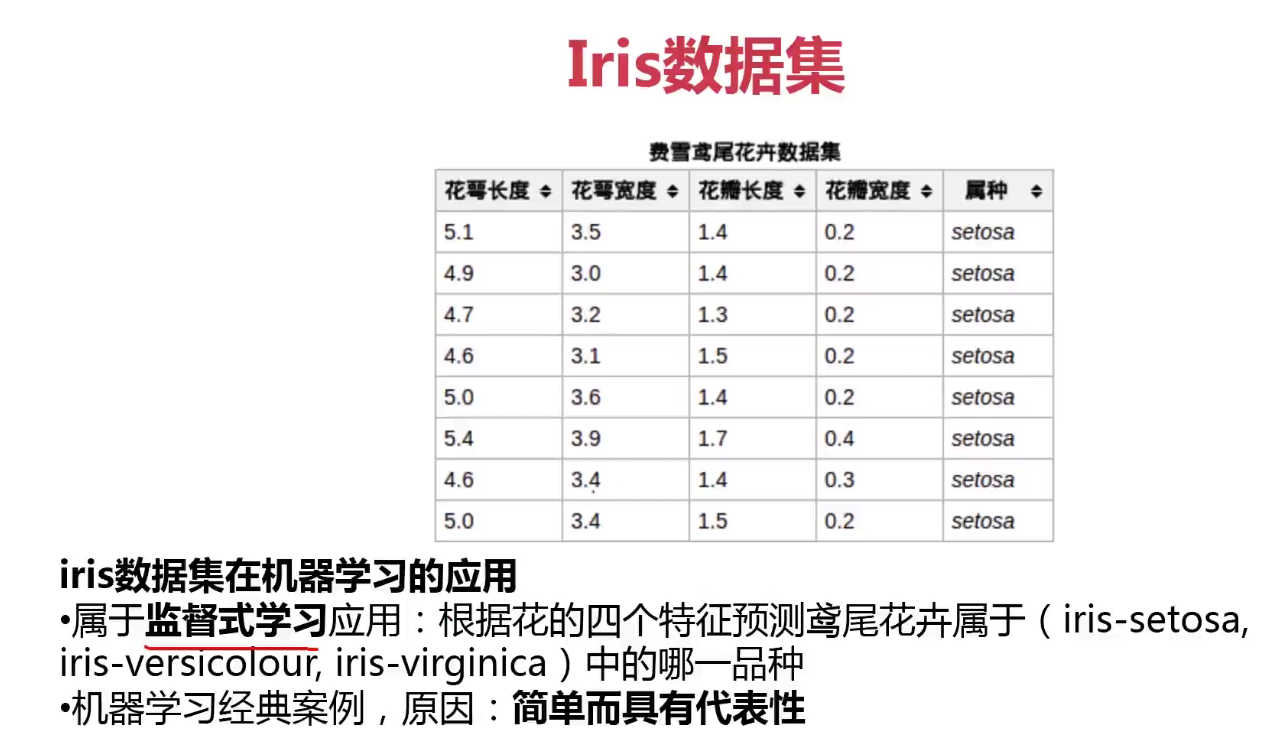
#Iris数据加载
import numpy as np
from sklearn import datasets
iris=datasets.load_iris()
print(iris.data)#输出属性数据内容
print(iris.feature_names)#输出每一列对应的属性名称
#['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
print(iris.target)#输出每一行数据对应的结果的名称
# [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
# 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
# 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
# 2 2]
print(iris.target_names)#输出结果依次对应的数据含义
#['setosa' 'versicolor' 'virginica']
2)使用scikit-learn进行数据处理的四个关键点
①区分开属性数据和结果数据
②属性数据和结果数据都是量化的
③运算过程中,属性数据与结果数据的类型都是numpy数组
④属性数据与结果数据的维度是对应的,即行数应该对应
4.机器学习实现之模型训练
1)分类:根据数据集目标的特征或属性,划分到已有的类别中
2)常用的算法:K近邻(KNN),逻辑回归,决策树,朴素贝叶斯
3)K近邻分类模型(KNN):给定一个训练数据集,对新的输入实例,在训练的数据集中找到与该实例最邻近的K个实例,这个K实例的多数属于某一类,就把该输入实例归到这个类中
4)使用scikit-learn进行建模的四个步骤:
①调用需要使用的模型类
②模型初始化:创建一个模型实例
③模型训练
④模型预测
#Iris数据加载
import numpy as np
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier#模型调用,KNN的分类器
iris=datasets.load_iris()
X=iris.data#属性数据
Y=iris.target#结果数据
print(X.shape)#确认属性数据和结果数据的维度是否相同
print(Y.shape)
#创建实例
knn=KNeighborsClassifier(n_neighbors=1)#n_neighbors即为K,KNN的其他参数自行了解
#模型训练
knn.fit(X,Y)
#模型预测
x_test=[[1,2,3,4],[2,3,1,4]]
result=knn.predict(x_test)#进行预测
print(result)#输出结果[2 0]
#当我们把K设置为5,输出结果为[1 0]
5.机器学习实现之模型评估
1)为了对模型的准确率进行评估,我们不能用全部的数据进行训练,因为这样无法判断模型的准确性,不妨将数据集分为训练集与测试集两部分,一部分用于训练,一部分用于测试,这样便于对模型进行评估,下面是不进行数据分离的结果,显然K=1时,正确率100%
#Iris数据加载
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier#模型调用,KNN的分类器
from sklearn.metrics import accuracy_score#用于判断准确率
iris=datasets.load_iris()
X=iris.data#属性数据
Y=iris.target#结果数据
#创建实例
knn=KNeighborsClassifier(n_neighbors=5)#n_neighbors即为K,KNN的其他参数自行了解
#模型训练
knn.fit(X,Y)
Y_pred=knn.predict(X)#预测后的数据
print(accuracy_score(Y,Y_pred))#准确率计算
#0.9666666666666667
2)下面进行数据分离然后进行模型评估
#Iris数据加载
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier#模型调用,KNN的分类器
from sklearn.metrics import accuracy_score#用于判断准确率
from sklearn.model_selection import train_test_split#用于进行数据分离
iris=datasets.load_iris()
X=iris.data#属性数据
Y=iris.target#结果数据
#创建实例
knn=KNeighborsClassifier(n_neighbors=5)#n_neighbors即为K,KNN的其他参数自行了解
#模型训练
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.4)#数据分离
#X_train,Y_train为用于进行训练的数据,X_test,Y_test为用于进行测试的数据,test_size为用于进行测试的数据比例
knn.fit(X_train,Y_train)
Y_pred=knn.predict(X_test)
print(accuracy_score(Y_test,Y_pred))
3)确定最合适的K值,遍历所有可取的K值
#Iris数据加载
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier#模型调用,KNN的分类器
from sklearn.metrics import accuracy_score#用于判断准确率
from sklearn.model_selection import train_test_split#用于进行数据分离
iris=datasets.load_iris()
X=iris.data#属性数据
Y=iris.target#结果数据
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.4)#数据分离
source_test=[]#存储评估准确率
for k in range(1,26):
knn=KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train,Y_train)#训练
Y_pred=knn.predict(X_test)
source_test.append(accuracy_score(Y_test,Y_pred))
#准确率结果可视化
plt.plot(range(1,26),source_test)
plt.xlabel("K(KNN model)")
plt.ylabel("Testing Accuracy")
plt.show()
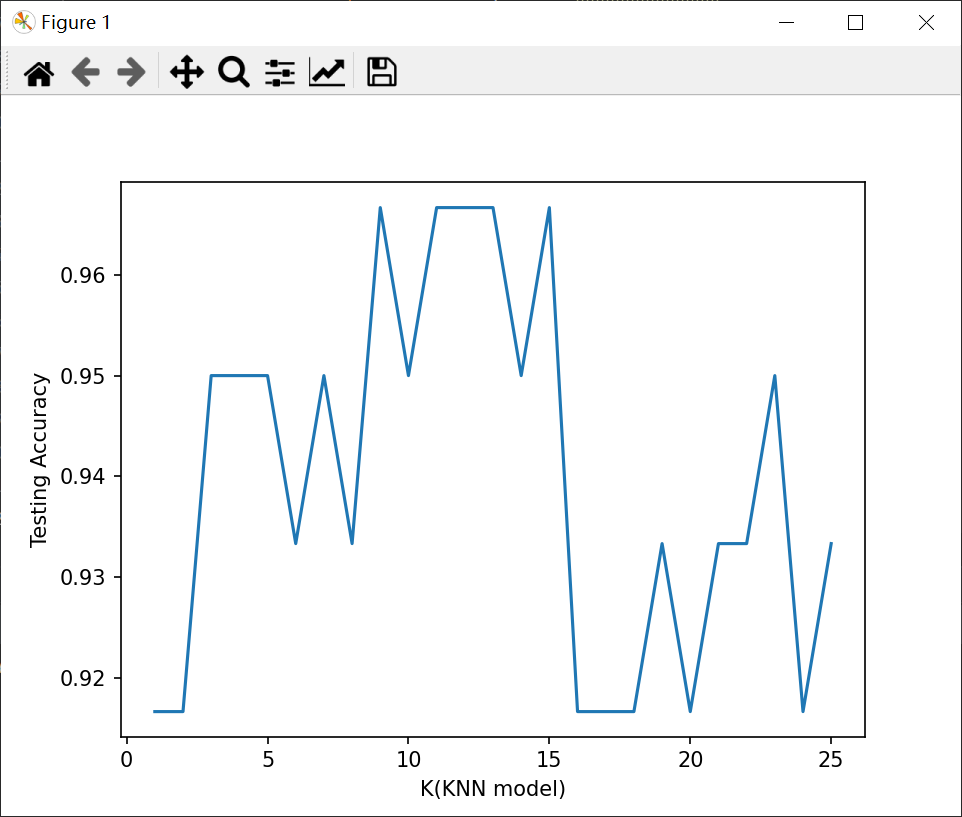
K值越小,模型越复杂,并且因为每次数据分离是随机的,训练出的结果也不相同
6.逻辑回归模型
1)逻辑回归模型:用于解决分类问题的一种模型。根据数据特征或属性,计算其归属于某一类别的概率P(x) ,根据概率数值判断其所属类别。主要应用场景: 二分类问题。
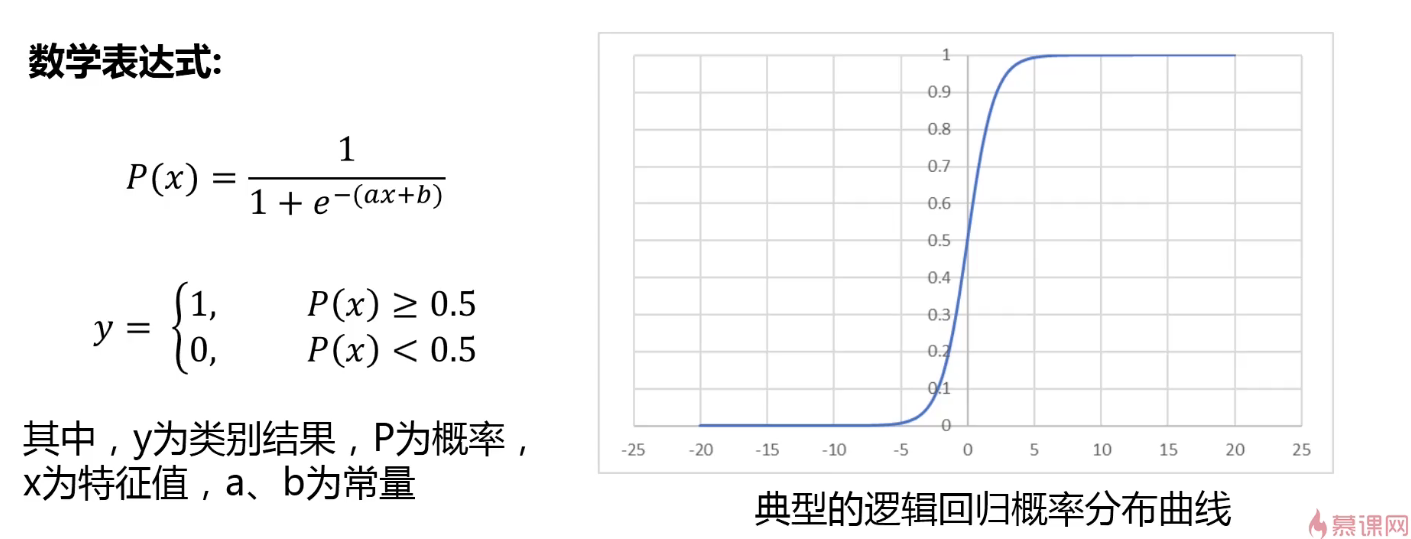
2)皮马印第安人糖尿病数据集

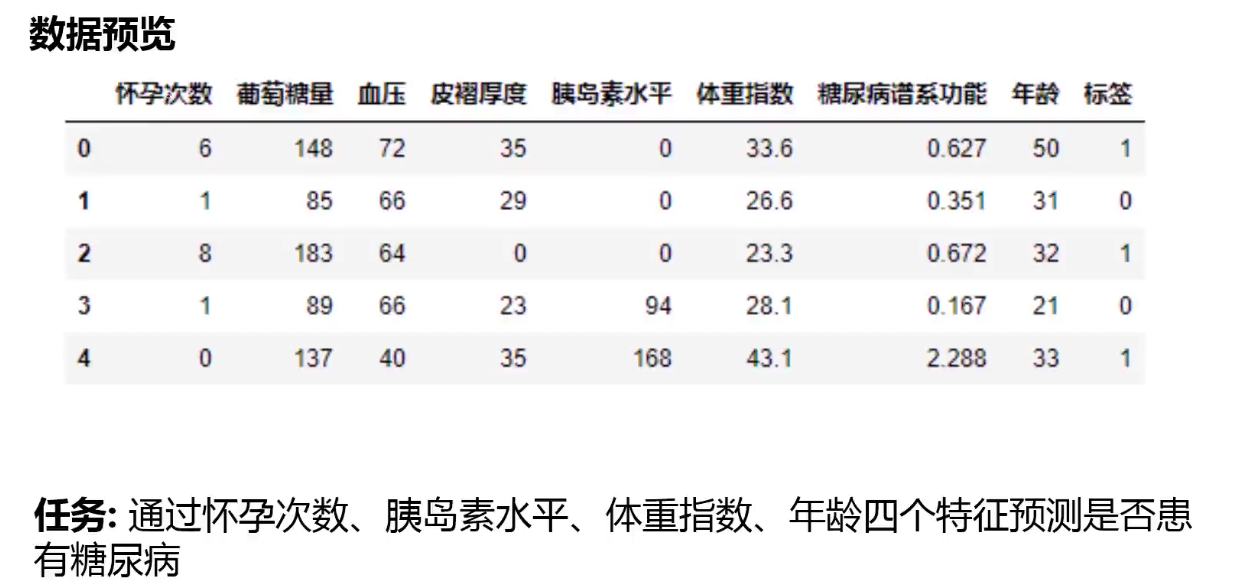
注意数据集的特点是有缺失数据
3)使用准确率进行模型评估的局限性:没有体现数据的实际分布情况,没有体现模型错误预测的类型
空准确率:当模型总是预测比较高的类别,其预测准确率的数值,即比例较高的类别在模型中所占的比例
4)混淆矩阵
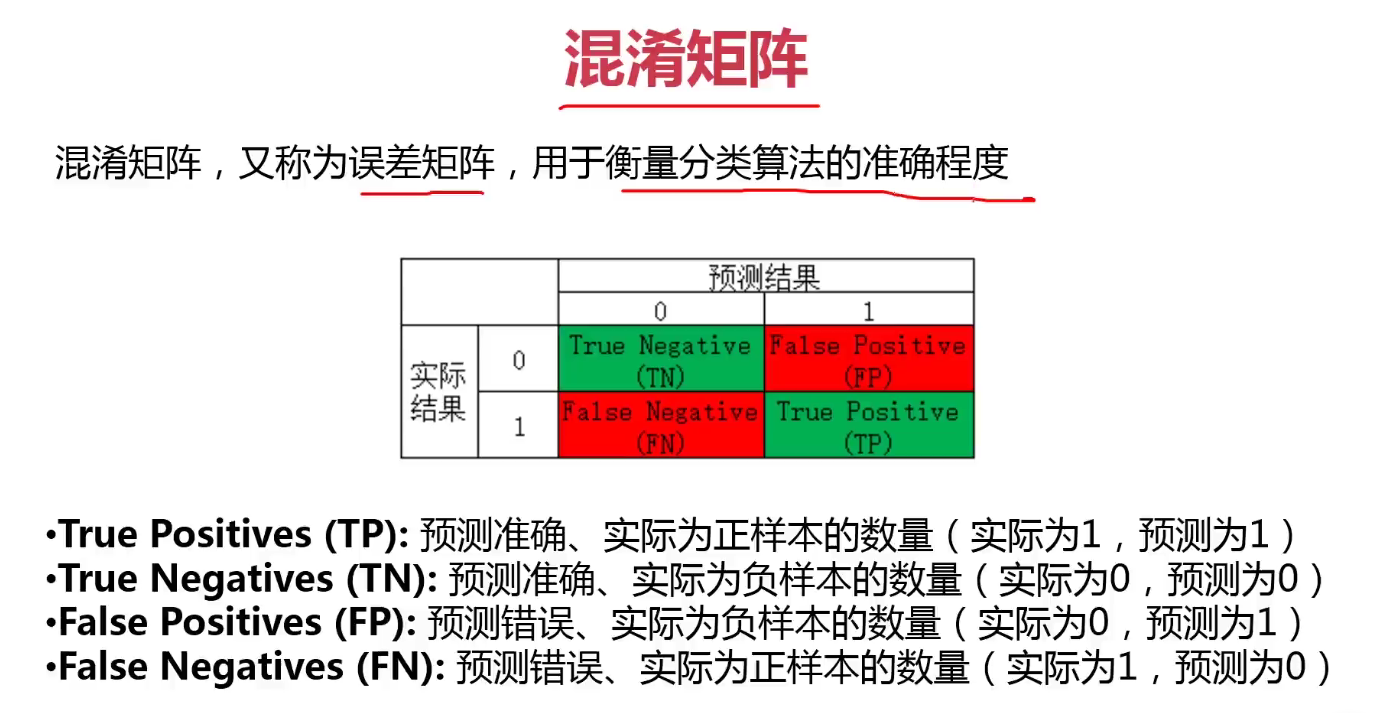
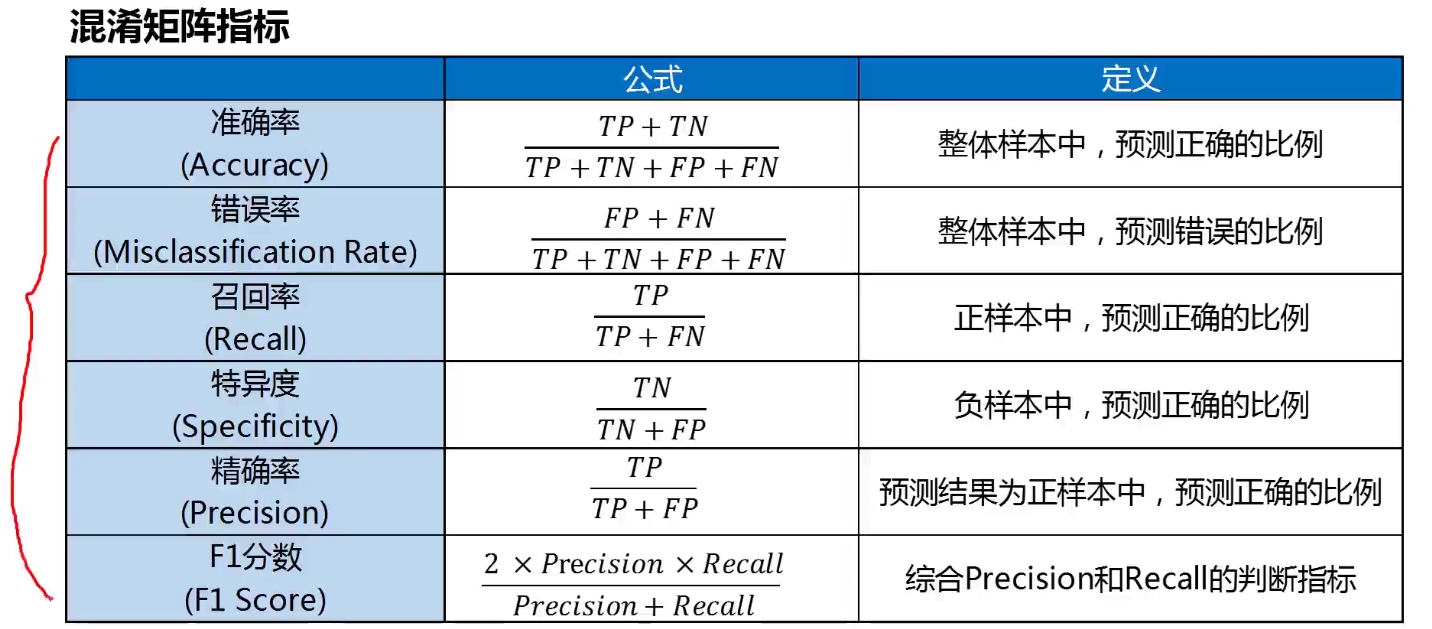

import pandas as pd
from sklearn.linear_model import LogisticRegression#导入逻辑回归模型
from sklearn import metrics
from sklearn.model_selection import train_test_split#用于进行数据分离
pima=pd.read_csv("F:/tmp/diabetes.csv")#导入数据
X=pima.loc[:,'Pregnancies':'Age']#属性数据
Y=pima.Outcome#结果数据
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.4,random_state=0)#数据分离
#random_state=0指每次数据分离不再随机
logreg=LogisticRegression()#创建模型实例
logreg.fit(X_train,Y_train)#模型训练
Y_pred=logreg.predict(X_test)#模型预测
print(metrics.accuracy_score(Y_test,Y_pred))#预测准确率0.8084415584415584
#实际结果情况
print(Y_test.value_counts())
#0 205
#1 103
#Name: Outcome, dtype: int64
#1的比例
print(Y_test.mean())#求平均即为1的比例0.3344155844155844
#0的比例
print(1-Y_test.mean())#0.6655844155844156
#空准确率
print(max(Y_test.mean(),1-Y_test.mean()))#0.6655844155844156
计算混淆矩阵进行模型评估
print(metrics.confusion_matrix(Y_test,Y_pred))#计算混淆矩阵
#[[191 14]
# [ 45 58]]
[[TN,FP],[FN,TP]]=metrics.confusion_matrix(Y_test,Y_pred)#计算混淆矩阵,并赋值给各个因子
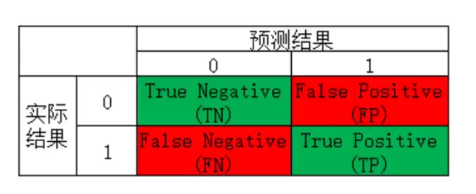
import pandas as pd
from sklearn.linear_model import LogisticRegression#导入逻辑回归模型
from sklearn import metrics
from sklearn.model_selection import train_test_split#用于进行数据分离
pima=pd.read_csv("F:/tmp/diabetes.csv")#导入数据
X=pima.loc[:,'Pregnancies':'Age']#属性数据
Y=pima.Outcome#结果数据
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.4,random_state=0)#数据分离
#random_state=0指每次数据分离不再随机
logreg=LogisticRegression()#创建模型实例
logreg.fit(X_train,Y_train)#模型训练
Y_pred=logreg.predict(X_test)#模型预测
[[TN,FP],[FN,TP]]=metrics.confusion_matrix(Y_test,Y_pred)#计算混淆矩阵,并赋值给各个因子
accuracy=(TP+TN)/(TP+TN+FP+FN)#准确率
print(accuracy)# 0.8084415584415584
mis_rate=(FP+FN)/(TP+TN+FP+FN)#错误率
print(mis_rate)# 0.19155844155844157
recall=TP/(TP+FN)#召回率
print(recall)# 0.5631067961165048
specificity=TN/(TN+FP)#特异度
print(specificity)# 0.9317073170731708
precision=TP/(TP+FP)#精确率
print(precision)# 0.8055555555555556
f1_score=(2*precision*recall)/(precision+recall)#F1分数
print(f1_score)# 0.6628571428571429







:机器学习导论.jpeg)