




:机器学习导论.jpeg)
机器学习实战(一):机器学习导论
机器学习导论
一、什么是机器学习
机器学习是人工智能的一个分支,涉及算法的设计和开发,允许计算机根据经验数据进化行为。由于智能需要知识,计算机必须获取知识。Tom Mtichell于1997年对机器学习的定义:一个计算机程序A,从经验E中学习关于某个任务T的性能度量P,E有助于提高计算机在任务T上的性能表现,这是基于统计和优化的,而不是基于逻辑的。
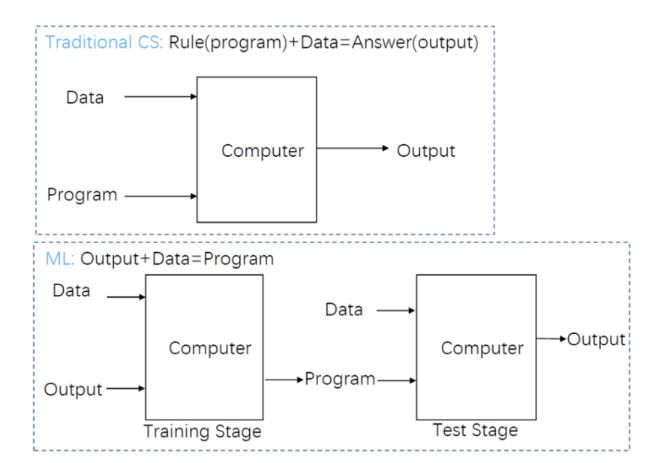
二、ML VS CS
机器学习的核心是程序,但是最终目标是结果。以垃圾邮件分类为例,我们所要研究的是进行分类的算法,但是我们的最终目标是邮件的类型。而传统的计算机科学则是根据一定的逻辑规则由输入得到正确的输出。
三、基本分类
3.1 监督学习
在监督学习(supervised learning)的过程中,算法从我们所提供的数据集中进行学习。
监督学习与非监督学习的最大区别在于我们知道用于训练的数据集的正确结果或期望输出,算法对验证集进行预测,由监督者对预测结果进行评估与纠正,进而优化算法,当算法达到可接受的性能水平时,则停止学习。
监督学习有两种主要类型:分类与回归
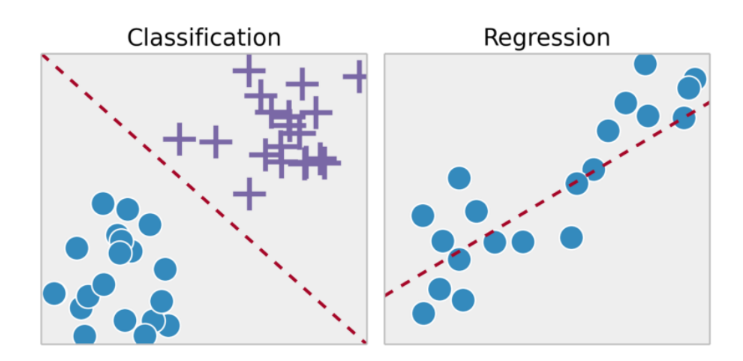
3.1.1 分类问题
顾名思义,就是根据特征对事物进行分类,一些经典的分类问题例子:
①垃圾邮件过滤问题:根据邮件内容对邮件是否为垃圾邮件进行分类,这是一个二分类问题。

②人脸识别问题:显然这就是一个多分类问题,根据照片中所包含的数据判断出人脸所对应的身份

3.1.2 回归问题
回归用于预测输入和输出变量之间的关系,特别是当输入变量的值发生变化时,输出变量的值也随之发生变化,经典的回归问题如下:
①房价预测:根据所提供的相关特征对某个楼盘的房价进行预测
②天气预测:根据相关指标对未来的天气,例如PM2.5值进行预测
3.2 非监督学习
无监督学习(unsupervised learning)是一类用于在数据中寻找模式的机器学习技术。无监督学习算法使用的输入数据都是没有标注过的,这意味着数据只给出了输入变量(自变量 X)而没有给出相应的输出变量(因变量y)。
在无监督学习中,算法本身将发掘数据中有趣的结构。人工智能研究的领军人物 Yann LeCun,解释道:无监督学习能够自己进行学习,而不需要被显式地告知他们所做的一切是否正确。
非监督学习最为经典的例子便是聚类问题。
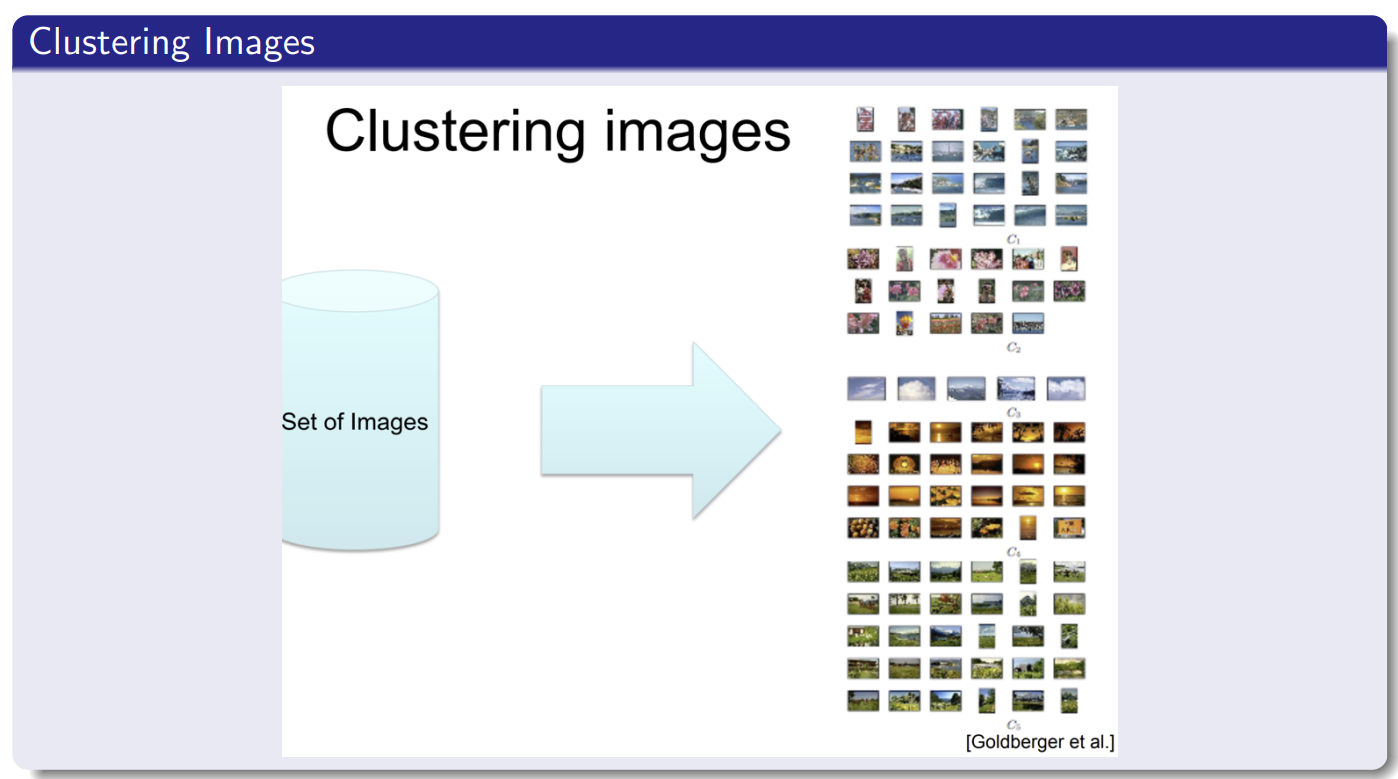
3.2.1 聚类问题
顾名思义,聚类就是根据所提供的相关数据,对具有相似特征的事物进行分类,比如照片的类型、网页主题的聚类。
在后期的学习中我们主要关注监督学习的相关算法。
3.3 强化学习
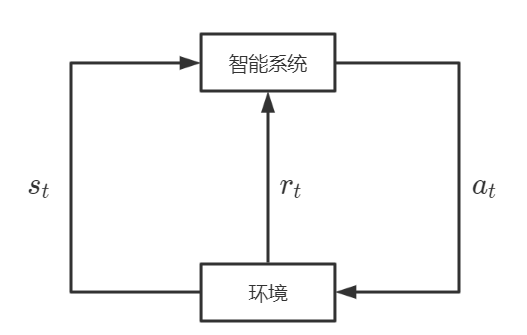
强化学习(reinforcement learning)是指智能系统在与环境的连续互动中学习最优化行为策略的机器学习问题,强化学习的本质是学习最优的序贯决策。
智能系统与环境的互动如下图所示,在每一步t,智能系统从环境中观测到一个状态(state)与一个奖励,采取一个动作(action)。环境根据只能系统选择的动作,决定下一步t+1的状态与奖励。要学习的策略表示为给定的状态下采取的动作。
智能系统的目标不是短期奖励的最大化,而是长期累积奖励的最大化,强化学习的过程中系统不断试错,以达到学习最优策略的目的。
3.4 半监督学习
半监督学习(semi-supervised learning)是指利用标注数据和未标注数据学习预测模型的机器学习问题。通常有少量标注数据、大量未标注数据,因为标注数据的构成往往需要人工,成本较高,未标注的数据的收集则不需要太多成本,半监督学习旨在利用未标注数据中的信息,辅助标注数据,进行监督学习,以较低的成本达到较好的学习效果。
四、经典的机器学习过程
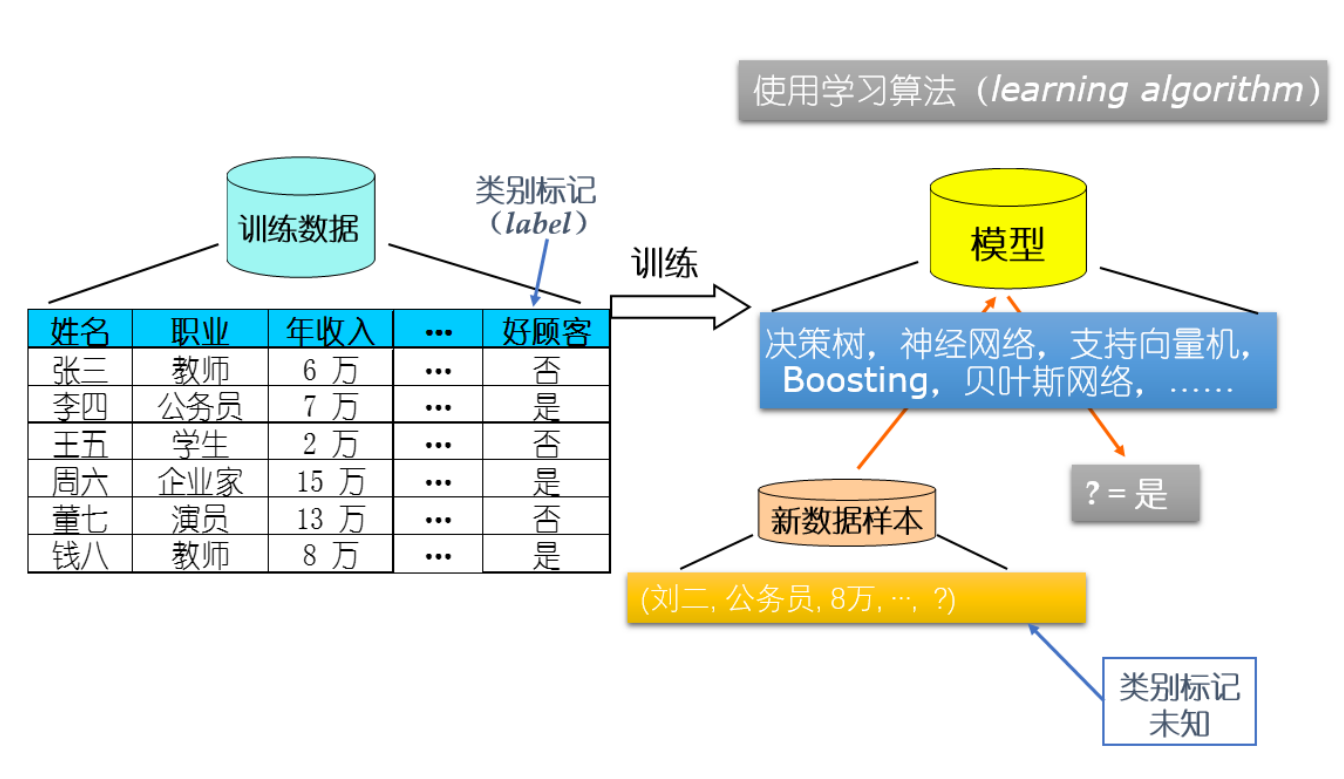
如下图所示,这是一个属于监督学习的二分类问题的机器学习过程,通过所提供的训练数据使用学习算法训练出模型,再将我们所要预测的不带标签(label)的新数据样本输入到模型中去,进而预测出该样本所属的类别。
在后续的博客中,我将会介绍机器学习中的重要概念与相关算法,还请大家多多支持与关注😄!







:监督学习.png)
